结构性测试(白盒测试)
结构性测试方法:
- 路径测试
- 数据流测试
基于路径的测试
程序流图
1.Program triangle2
2.Dim a,b,c as Integer
3.Dim IsATriangle As Boolean
4.OutPut(“Enter 3 integer which are sides of a triangle”)
5.Input(a, b, c)
6.OutPut(“Side A is “, a)
7.OutPut(“Side B is “, b)
8.OutPut(“Side C is “, c)
9.If (a < b + c) AND (b < a + c) AND (c < a + b)
10. Then IsATriangle = True
11. Else IsATriangle = False
12.EndIf
13.If IsATriangle
14.| Then If (a = b) AND (b = c)
15.| | Then Output(“等边三角形”)
16.| | Else If (a<>b) AND (a <> c) AND (b <> c)
17.| | | Then Output(“一般三角形”)
18.| | | Else Output(“等腰三角形”)
19.| | EndIf
20.| EndIf
21.Else Output(“非三角形”)
22.EndIf
23.End triangle2
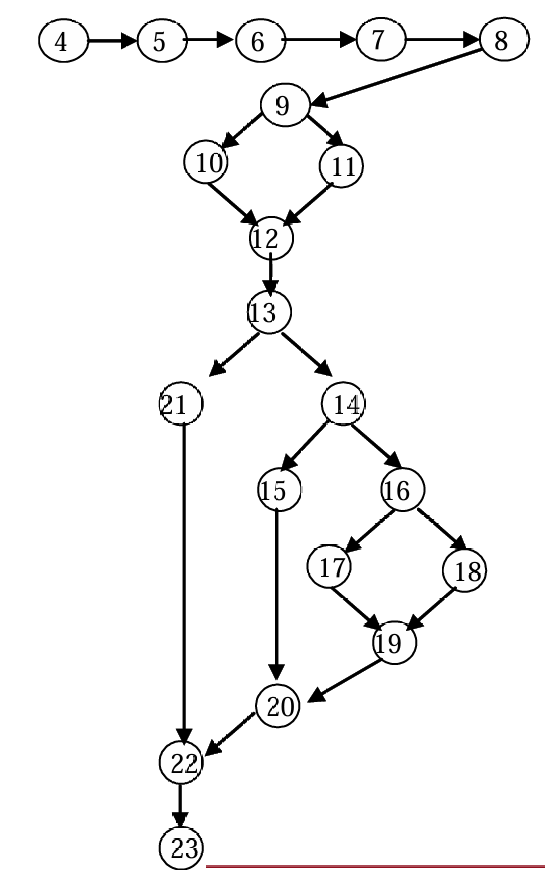
由于程序流图没有严格的规范,所以需要统一为DD-路径
DD-路径的定义:
DD-路径是程序图中的一条链,使得(程序流图仅由以下五种情况组成):
- 情况1:由一个节点组成,入度=0。
- 情况2:由一个节点组成,出度=0。
- 情况3:由一个节点组成,入度≥2或出度≥2。
- 情况4:由一个节点组成,入度=1并且出度=1。
- 情况5:长度≥2的最大链(单入单出的最大序列)。
语句覆盖:使程序中每一可执行语句至少执行一次
分支覆盖:使程序中的每个逻辑判断的取真取假分支至少经历一次
条件覆盖:所有判断的每种分支(每个分支可能有多个判断条件,比如if A or B,条件覆盖需要A和B都取过T/F,如TT,FF)
多条件覆盖(条件组合覆盖):使得每个判断表达式中条件的各种可能组合都至少出现一次(对于每个判断条件,覆盖所有取值可能,比如if A or B,多条件覆盖需要TT,TF,FT,FF四种都覆盖)
分支/条件覆盖:既满足分支覆盖,又满足条件覆盖
路径覆盖:覆盖所有可能的路径组合
基本路径:
- 必须从程序起点到程序终点
- 必须包含其他基本路径没用到的边,或者引入一个新处理语句/新判断
通过基本路径的线性组合可以得到所有路径
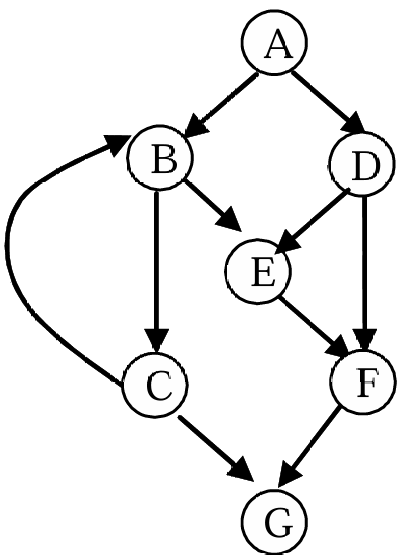
上图的基本路径:
- P1:A,B,C,G
- P2:A,B,C,B,C,G
- P3:A,B,E,F,G
- P4:A,D,E,F,G
- P5:A,D,F,G
圈复杂度:V(G)=e-n+2p
e为边数,n为节点数,p为连通部件数(因为程序必定连通,所以p≡1)
对于上图:e=10,n=7,p=1,V(G)=5
另:如果是强连通图(存在一条从终点指向起点的路径,即整个程序是一个强连通分量,则V(G)=e-n+p)
圈复杂度的另一种计算方法:判定节点的数量+1
判定节点:if; while; for; case; catch; and,or; 三元运算符
1(while) + 1(while) + 1(if) + 1 = 4
void sort(int *A)
{
int i = 0;
int n = 5;
int j = 0;
while (i < (n - 1))
{
j = i + 1;
while (j < n)
{
if (A[i] < A[j])
{
swap(A[i], A[j]);
}
}
i = i + 1;
}
}1(for) + 2(if) + 1 = 4
int find (int match)
{
for (int var in list)
{
if (var == match && var != NAN)
{
return var;
}
}
}数据流测试
定义-使用(def-use)测试
定义节点:输入语句、赋值语句、循环控制语句、过程调用语句
使用节点:输出语句、赋值语句、条件语句、循环控制语句和过程调用语句,都是可能的使用语句。但它们不改变变量的值。
7. lockPrice=45.0
8. stockPrice=30.0
9. barrelPrice=25.0
10. totalLocks=0
11. totalStocks=0
12. totalBarrels=0
13. Input(Locks)
14. While NOT(Locks==-1)
15. | Input(stocks,barrels)
16. | totalLocks=totalLocks+Locks
17. | totalStocks=totalStocks+stocks
18. | totalBarrels=totalBarrels+barrels
19. | Input(Locks)
20. ENDWhile
21. Output(“Locks sold:”,totalLocks)
22. Output(“Stocks sold:”,totalStocks)
23. Output(“Barrels sold:”,totalBarrels)
24. lockSales=lockPrice*totalLocks
25. stockSales=stockPrice*totalStocks
26. barrelSales=barrelPrice*totalBarrels
27. Sales=lockSales+stockSales+barrelDSales
28. Output(“Total Sales: ”,Sales)
29. If (sales>1800)
30. Then
31. | commission=0.10*1000.0
32. | commission=commission+0.15*800.0
33. | commission=commission+0.20*(sales-1800.0)
34. | Elseif(sales>1000.0)
35. | Then
36. | | commission=0.10*1000.0
37. | | commission=commission+0.15*(sales-1000.0)
38. | Else
39. | | commission=0.10*sales
40. | EndIf
41. EndIf
42. Output(“commission is $”,commission)
43. End commission| 变量名 | 定义节点 | 使用节点 |
| lockPrice | 7 | 24 |
| stockPrice | 8 | 25 |
| barrelPrice | 9 | 26 |
| totalLocks | 10,16 | 16,21,24 |
| totalStock | 11,17 | 17,22,25 |
| totalBarrels | 12,18 | 18,23,26 |
| locks | 13,19 | 14,16 |
| stocks | 15 | 17 |
| barrels | 15 | 18 |
| locksales | 24 | 27 |
| stocksales | 25 | 27 |
| barrelsales | 26 | 27 |
| sales | 27 | 28,29,33,34,37,39 |
| commission | 31,32,33,36,37,39 | 32,33,37,42 |
定义-使用路径du-path:以定义节点开头,使用节点结尾
定义-清除路径dc-path:以定义节点开头,使用节点结尾,且路径途中没有其他(该变量的)定义节点
定义-使用路径测试的覆盖指标
- 全定义准则:覆盖所有定义节点到一个使用节点的du-path
- 全使用准则:覆盖所有定义节点到所有使用节点的du-path
- ……
程序片:给定程序P,变量V,语句n,将P中所有对n处的V有贡献的语句集合定义为程序片,记作S(v,n)
比如示例程序中S(Locks,13)={13}; S(Locks,14)={13,14,19,20}; S(Locks,16)={13,14,19,20}
同时,如果变量V处于循环体/if-else语句中,则还会收到其他变量的影响,比如S(Stocks,15) ={13,14,15,19,20}
回归测试
回归测试:测试如何适应软件的迭代化开发
基本过程:
- 识别软件中被修改的部分
- 排除不再适用的测试用例,确定依然有效的测试用例,构建一个新的测试用例库
- 依照一定的策略,从测试用例库中测试被修改的软件
- 如有必要,生成新的用例库用于测试原有用例库无法测试到的软件
回归测试的用例选择方法:
- Test selection using execution trace(执行跟踪/执行路径) and execution slice(执行切片)
- Test selection using test minimization(测试最小化)
- Test selection using test prioritization
Test selection using execution traceand execution slice
- 找到每个测试用例的执行路径
- 提取出CFG(控制流图)中每个节点的测试向量(test vector)
- 构建原程序P和新程序P’的语法树(syntax trees)
- 遍历两个CFG,确定仍适用的测试用例(测试优先级)
考虑程序P,其源码如下,并根据源码构建出CFG,再根据CFG构建出每个节点的语法树

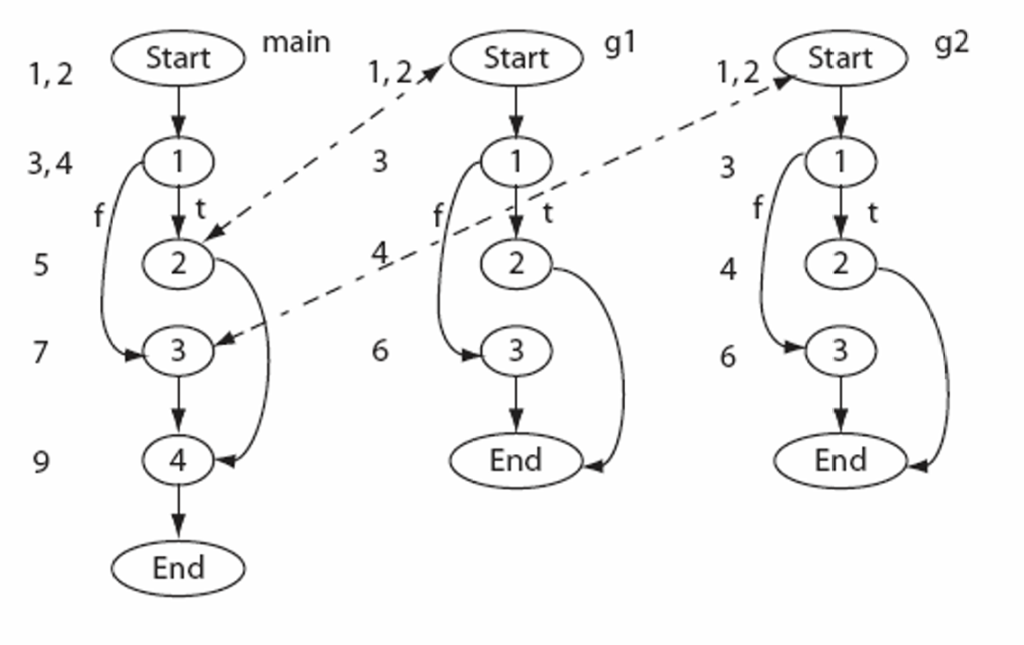
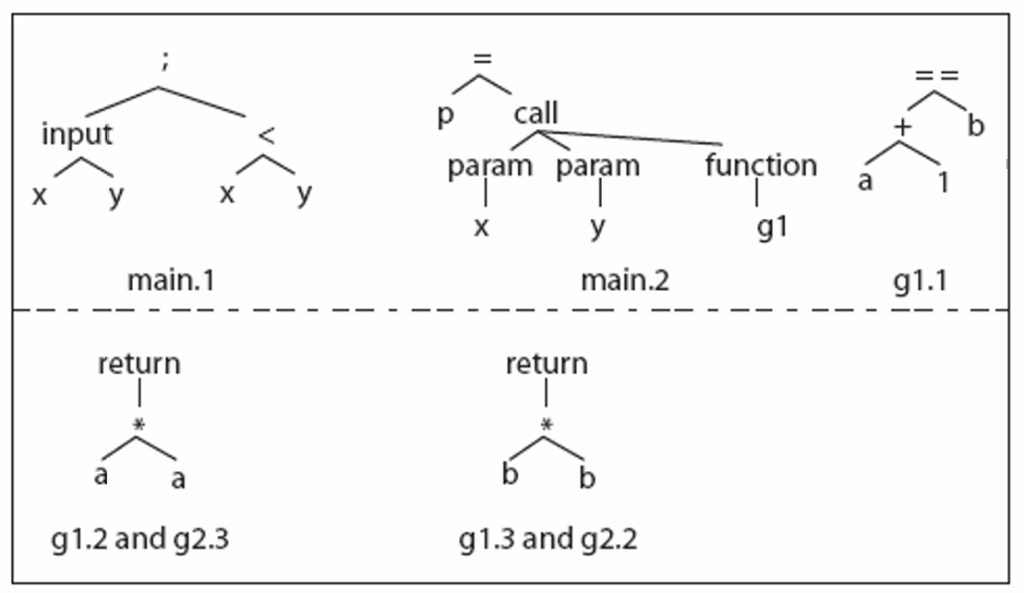
另有上次迭代遗留的三个测试用例如下,并可以推出其执行路径
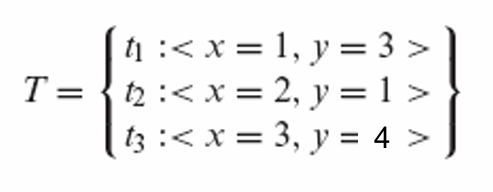

以此得到测试向量:

然后根据P和P’的CFG及语法树,递归比较语法树,如果发现不同之处,则将经过该节点的测试用例添加到新的测试用例中(只测试修改的部分)
Test selection using test minimization
首先需要定义“测试实体”:可以是函数,可以是一个代码块
程序P有main和f两个函数,测试用例t1仅运行main,测试用例t2运行main和t2,现在假定程序P修改f后变成了P‘,显然我们没有必要再运行t1的测试。
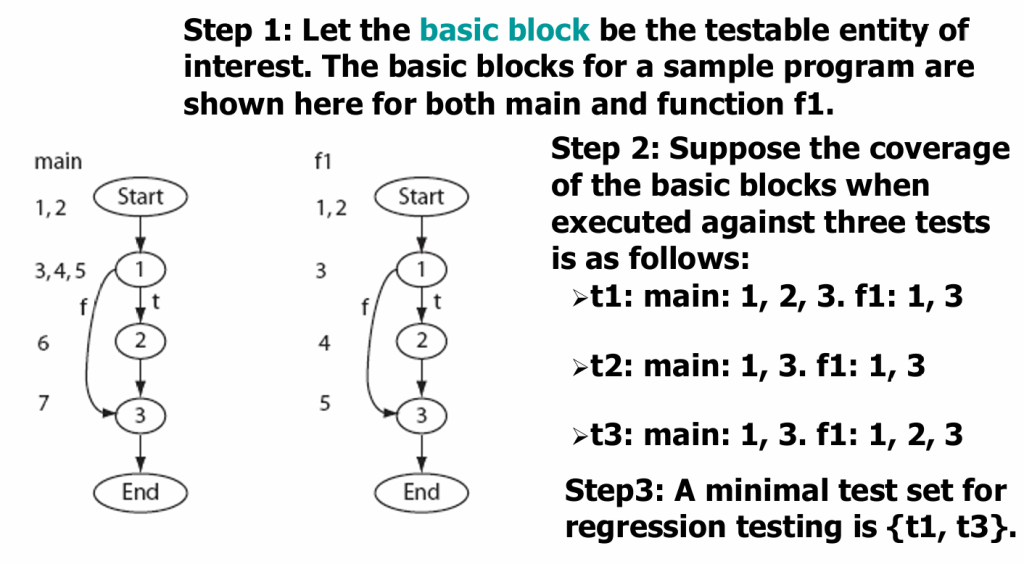
Test selection using test prioritization
需要定义测试的优先级,只测试优先级高的。
变异测试
不使用覆盖率,从另一个角度评价测试的充分性。
如何定义测试的充分性?
对于原程序P的修改程序P’,如果P’能通过P的测试集T,则T是不充分的。T能否区分P和P’代表了T的充分性。当然也有特殊情况,比如冒泡排序和快排的结果一定是相同的,这种情况下P‘是P的等价变异体。
- 生成k个变异体
- 对每个变异体运行测试T,如果有未通过的测试则不再考虑此变异体
- 如果所有变异体都被区分了,说明测试T是足够的;如果有k1个变异体未被区分,则定义mutation score (MS,变异分数)MS=k1/(k-e),e为变异体中等价变异体的数量。
MS=1,说明T区分了所有的非等价变异体,测试是充分的;否则是不充分的。测试充分性和自行设计的变异体有关
例:
原程序:input(x,y); return x-y;
T:{t1:x=1,y=0; t2:x=-1,y=0}
生成变异体:x+y;x-0;0+y;
对生成的三个变异体测试,则有
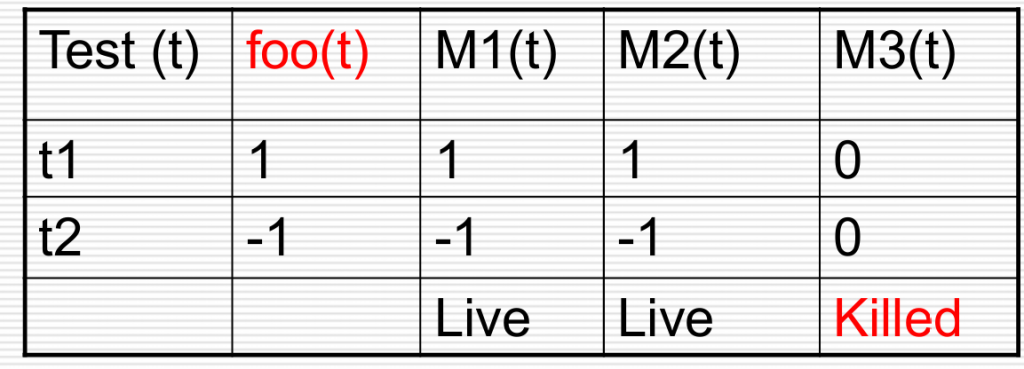
变异体一般通过简单的修改生成,比如运算符号的替换等等。替换一处叫一阶变异体,替换多处叫多阶变异体。考虑到程序员一般会出简单的错误(熟练程序员假设),因此一般使用一阶变异体。