Overview
后端开发
- Lec1:实例管理
- Lec2-3:异步通信JMS、Kafka、WebSocket
- Lec4-5:事务管理
- Lec6:Java多线程
- Lec7:分布式缓存Redis
- Lec8:全文搜索
- Lec9:Web服务
- Lec10:微服务Eureka
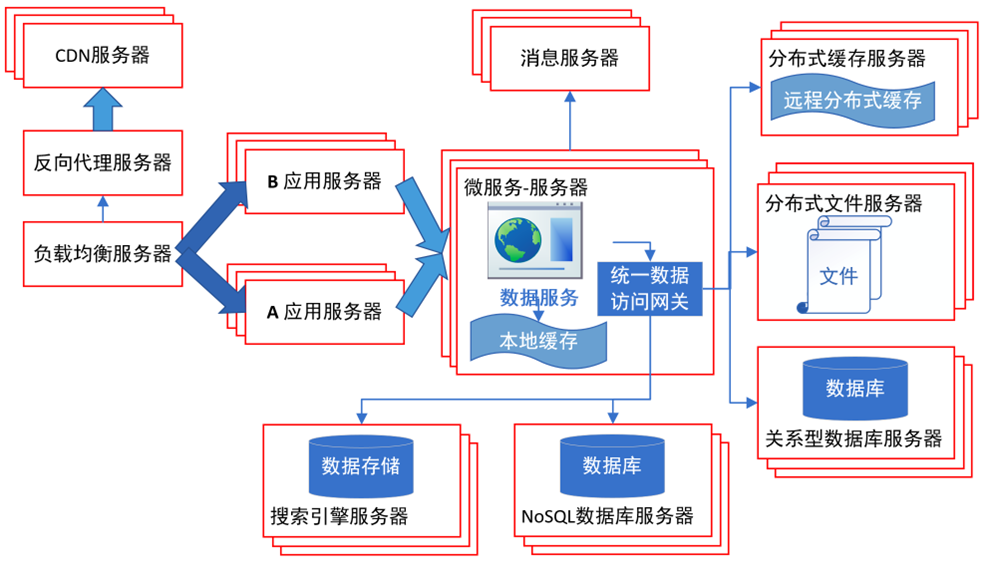
最终效果:
数据库
- Lec11-12:MySQL优化
- Lec13:MySQL备份与恢复
- Lec14:MySQL分区
- Lec15:NoSQL-MongoDB
- Lec16:NoSQL-Neo4j
- Lec17:NoSQL-VectorDB & LogStructureDB
- Lec18:NoSQL-TSDB InfluxDB
- Lec19-20:云数据库GuassDB、数据湖
集群
- Lec21:集群部署-Nginx
- Lec22:容器化-Docker
- Lec23:批数据并行处理-Hadoop
- Lec24:批数据并行处理-Spark
- Lec24:流数据并行处理-Storm
- Lec25:分布式文件系统-HDFS
- Lec26:分布式数据库-HBase
- Lec27:分布式数据仓库-Hive
- Lec27:分布式并行处理框架-Flink
oneAPI
人工智能
- Lec21:神经网络
- Lec22:卷积神经网络CNN
- Lec23:自然语言处理
- Lec24:循环神经网络RNN
- Lec25:ChatGPT
- Lec27:Transformer
后端开发
实例管理
有状态服务和无状态服务
有状态服务:需要区分用户的服务,甚至单个用户的每次服务都不一样。状态需要保存,过多会爆内存,或者换页导致大量IO,内存大小通过实例池大小控制
无状态服务:无需对用户进行区分的服务,可以启动无数个以应对请求;无状态的极致是函数式编程
实例作用域
| Scope作用域 | 解释 |
|---|---|
| singleton单例 | 整个 Spring 容器中只创建一个实例,全局共享 |
| prototype原型 | 每次调用时都会创建一个新实例,比如controller调用service会创建新的。 |
| request | 每次HTTP请求都一个新实例,适合与请求相关的数据处理,比如请求参数校验等。 |
| session | 每个 HTTP 会话周期内都会有独立的 Bean 实例,适合用户登录状态,在一个session内多个http只有一个实例。 |
| application | Bean 的生命周期与整个 Web 应用的生命周期一致,适合存储全局配置、共享资源等。和singleton区别是用在web。 |
| websocket | 每个 WebSocket 会话创建一个 Bean 实例,适合实时通信场景下与单个用户连接相关的数据或状态。 |
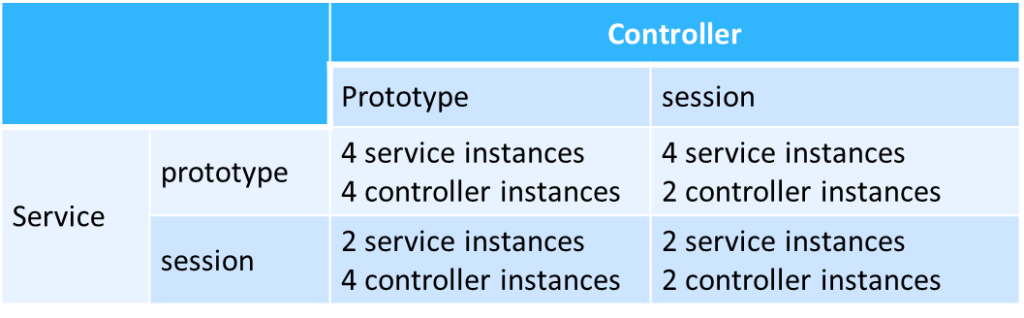
分别使用两个浏览器,每个发两次请求,controller和service采用不同的scope,会得到不同的实例数量
连接池大小:大核*2+小核+有效硬盘数(真硬盘,分区不算)
与用户数无关,唯一准则是减少线程切换及IO等待
例:
- CPU:12th Gen Intel(R) Core(TM) i7-12700H 内核:14 逻辑处理器: 20
- 磁盘 0 (C:)SKHynix_HFS512
- 磁盘 1 (D: E:)WD_BLACK SN770 1TB
连接池大小:20+2=22
异步通信JMS、Kafka、WebSocket
同步通信:请求→执行→返回,负载大时速度慢,甚至会崩溃。缺点:紧耦合;不保证成功服务;前后端契约;没有请求缓冲;过于强调返回值;请求不可重做
异步通信:请求→存储→返回一个响应→执行→返回结果。缺点:各种消息组装编程难度大
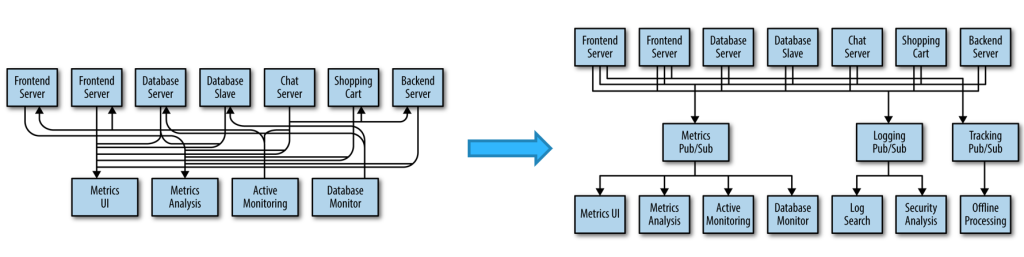
消息中间件-Kafka的原理:包含不同topic,controller将请求存储在对应的topic,service监听topic
结果如何返回给客户端?
前端Ajax轮询、WebSocket、发送message到某个topic等待前端查看
松散耦合:订阅topic的service可以使用任意方法处理订单,而非严格调用。
什么情况下消息中间件可以扔掉消息(定时删除),什么时候不能扔(持久化):股票实时推送(不收到也没事);订单(不能缺失)
JMS API
是API,不是实现
特点
- 异步(receiver无需在消息送达时就接收消息,可以在很久后才接收)
- 可靠性:保证At-least-once以及At-most-once
两种模式
- 点对点:消息放在一个queue内,只有一个人可以拿取消息
- 广播-订阅:消息放到一个topic里,所有订阅者都可以拿取消息
Kafka
采用广播-订阅模式,订阅者在这里叫做消费者,系统间各个部件解耦
kafka采用流式数据存储,使用只追加的日志文件,每个消费者有一个自己的指针,用于标记读到了哪个消息
kafka也可以做集群加备份,消息通过哈希做分区
WebSocket
全双工通信协议:支持双向通信-服务器也可以主动发送消息
通信过程
- 握手:使用ws开头的url,发送一个http消息,Web服务器解释其为HTTP连接升级请求
- 数据传输
endPoint分为客户端和服务器端,服务器端等待与客户端连接;使用一个异步队列维护session;可以借助模板类编写自己class的编码器、解码器,可以自动转换成java对象。
前后端通信方式
- HTTP:全同步,前端等待时无法进行操作
- Ajax:前端异步,得到后端消息后执行回调,无需等待
- 后端异步:后端在处理大量请求时,先将消息存储,然后排队处理
- WebSocket:后端将结果主动发送给前端
四种方式选择:login显然不能做后端异步
事务管理
不使用事务的后果:两个人同时买书:卖重了?转账只扣钱没加钱?
使用事务管理
AICD属性
- atomic原子性:All-or-Nothing
- consistency一致性:事务在开始和结束时,数据库都必须符合所有预设的规则、约束和数据完整性条件。事务不能破坏数据库的规则或完整性约束。(例:假设有一个数据库规则,规定银行账户的余额不能为负数。一旦事务执行完成,数据库必须确保这个规则依旧成立,如果某个操作试图违反规则,事务将被回滚。)
- isolation隔离性:不会出现数据冲突(两个人同时改动又同时写入)
- durability持久性:事务除非被回滚,否则不会丢失
6种事务传播属性:
一个事务内的操作能够做到All-or-Nothing,出错就会被重置到之前的状态
- required:需要在事务中执行,如果没有会创建,如果有会加入
- requiresNew:无论之前有没有事务,都新建一个事务;如果之前有事务,则把之前的事务挂起,执行完恢复。新建事务和旧事务无关
- NotSupported:如果执行时有事务,则会把之前的事务挂起,然后执行
- Supports:可以不在事务中,有事务则加入
- Mandatory:必须已有事务
- Never:必须没有事务
脏读Dirty Read:读到了别的事务执行的中间状态
不可重复读:首先事务A读取,执行时事务B写入,然后事务A再次读取,数据不匹配(读取后加锁)
幻读:事务A在全表中做范围查找,做处理时B添加了数据,A再次读取时数据增多(读取后全表加锁)
4种事务隔离级别:
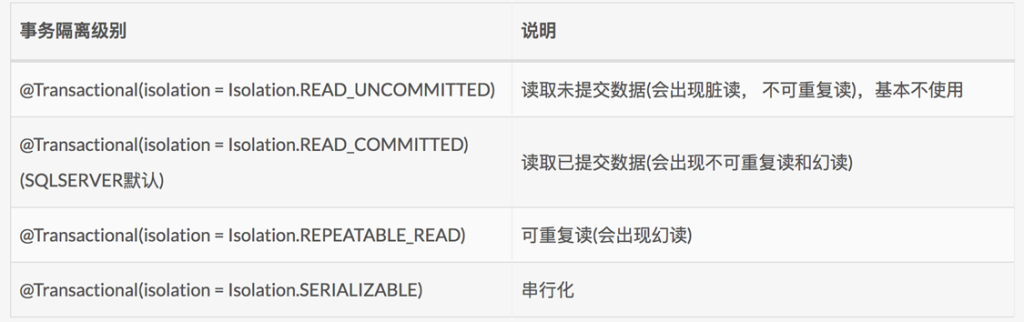
通过设置数据隔离级别,告诉数据库使用什么隔离级别。
如果涉及到多个数据库,比如从中行向光大转账,两个数据库不知道彼此存在,就需要单独的事务管理器(使用2PC等),但是无法避免网络错误等问题,需要人工处理。参照CSE:Multi-site transaction & Multi-site atomicity
我们也可以自己加锁,可以分为乐观锁(OCC/MVCC)和悲观锁,取决于程序员认为冲突发生的可能性高低,通过数据库版本号进行控制。
粗粒度锁:目标是同时锁住多个表,需要对整个表进行控制。两个表绑定同一个版本号即可
注意普通的java函数添加Transactional标签是没有意义的,标签时给数据库看的,对内存里的变量没有任何影响
实现事务管理
可串行化调度:参照CSE:实现Before-or-after(Serializability)
日志:
四种方法数据库恢复算法的及其优劣:内存占用、IO操作、数据恢复时间
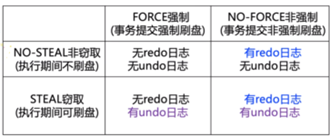
undo日志在写数据库之前,记录数据库修改前的值(防止事务回滚时无法恢复)
redo日志在写数据库之后,记录数据库修改后的值(防止提交后未刷盘导致的数据丢失)
日志写入是顺序写,顺序读,不修改;相较数据库的随机写速度很快。
逻辑日志:记录高层的抽象操作,例如用户输入的SQL语句
物理日志:记录数据库具体的物理变化,例如第10个page,offset为81-89的值修改为1
物理逻辑日志:在第10个page,执行xxx语句
物理日志与逻辑日志对比:
| 日志类型 | 解析速度 | 日志量 | 可重做性 | 幂等性 | 可逆性 | 应用场景 |
|---|---|---|---|---|---|---|
| 物理日志 | 快 | 大 | 是 | 是 | 否(offset可能因为其他修改而变化) | redo日志 |
| 逻辑日志 | 慢 | 小 | 否(插入到一半崩溃,再插入索引已被占用) | 否 | 是 | undo日志 |
| 物理逻辑日志 | 较快 | 中 | 是 | 否 | 否 | undo日志 |
Java多线程
带synchronized关键字的函数,会对这个类上锁,这个类的其他函数不能被调用,不会出现竞争的关系。(方法同步)
也可以在函数内的某一个部分使用synchronized关键字,只会对这一部分加锁。(语句同步)
带volatile关键字的变量,可保证操作是原子性的。
可重入锁:一个线程需要重复获取一个锁多次,需要使用可重入锁。
Java中除了long和double,其他基础类型的读写都是原子性的
锁的问题:死锁(deadlock)、活锁(livelock)、饥饿(starvation)
Starvation:是指如果线程T1占用了资源R,线程T2又请求封锁R,于是T2等待。T3也请求资源R,当T1释放了R上的封锁后,系统首先批准了T3的请求,T2仍然等待。然后T4又请求封锁R,当T3释放了R上的封锁之后,系统又批准了T4的请求……,T2可能永远等待。
数据库中会使用自旋锁,线程切换的切换比等待的时间还长的时候使用
不可变对象(Immutable Object)
解决了同一个线程两条语句(哪怕两个语句都是synchronized)之间,数据被其他线程修改的问题。在变量前标记final privite,无法执行写操作
高级特性:
- Lock对象:比一般的锁功能更多,提供了对锁的精细控制,特别适用于需要复杂同步控制的场景
- Executors线程池:提供了线程池管理的实现,可以创建固定大小的线程池、缓存线程池或单线程执行器。
- 并发数据结构:如ConcurrentHashMap通过分段锁技术,实现高效的并发操作,减少了锁竞争。
- Fork/Join框架:将问题划分成小的子问题,然后多线程执行
- 原子变量:如 AtomicInteger,通过硬件支持的原子操作(例如 CAS 操作)来保证数据的安全修改。
- 虚拟多线程:与平台线程相对应。一般的java线程数被cpu核数限制住,适合涉及大量IO操作的服务,用于在等待时间执行更多操作,而且不占用系统进程栈
分布式缓存Redis
Spring框架和数据库都有自己缓存,为什么我们还需要建立一块缓存?
——这两个缓存不受自己控制,可能不满足我们的需求;数据库可能不在同一个机器上;可以使用空间更大的分布式缓存
什么数据放缓存里?
——不经常改的,比如书的标题、简介;经常改的库存数据不要放缓存
如果所有修改都放在缓存中,隔一段时间刷盘可不可以?
——可以,但是要防止有其他应用绕过缓存读取数据库,必须全部被缓存拦截
缓存换页和数据库直接读取哪个快?
——缓存的是join后的数据,即使从磁盘读也可能更快;MySQL读取SQL语句的编译过程有消耗;一般缓存在主机上,或靠主机比较近
Memcached
数据以键值对形式存储,按照数据大小和名字进行分类便于快速找到数据;数据-节点的分配方式使用一致性hash(具体算法参照SE3331-Network-P2P Network-DHT分布式哈希表),方便增删节点。
Redis
Redis同样是一个内存中的键值对存储;与一般键值存储不同,redis除了字符串以外还支持更复杂的数据结构(string、list、set、hash等);且支持主从备份
Redis也可以用来实现类似于kafka的消息中间件
问题:
- 雪崩:启动时Redis读入大量数据,但过期时间是统一的,一旦全部过期会对数据库瞬间产生大量请求。设定随机过期时间即可
- 击穿:大量请求同时对一个不在Redis内的数据访问,全部访问数据库。读取上锁,在进入Redis前拦截
- 穿透:大量请求同时访问一个数据库中不存在的值,全部访问数据库。在Redis中缓存Bloom Filter,治标不治本。
全文搜索
为什么我们需要反向索引
——假设我们想要搜索书评中的关键字,使用一般的方式或浪费时间(全表扫描)或浪费空间(记录每条书评是否包含某个关键词),所以需要使用关键词作为索引,指向在文本中出现的次数及位置(用内容定位行)
Lucene
支持的功能:
- 关键词搜索
- 相似度排序(向量)
- 自定义索引(标题、正文等是否参与索引)
- 增量式(可以增删文章及关键词)
覆盖(召回)率和准确率需要权衡
Solr
基于Lucene,接口封装更简单;支持分布式、主从备份、负载均衡
Elasticsearch
将几个表合并成一个宽表,通过反向索引搜索一行内的多个字段是否含有关键词,然后回到原表中按索引拿取数据。
Web服务
如何通过网络请求与其他服务交互
方法调用
SOAP简单对象访问协议——传递方法的调用,包括url、方法名及变量等,并支持不同网络协议。
暴露在外面的是一个.WSDL文件,记录了如何通过各类协议及语言进行调用,并可以自动封装及解析。
消息传递使用XML格式的信封体,可以使用java插件自动解析。
还可以做一个注册表,防止不知道服务在哪里
优点:无需改动代码,可以生成多种语言的接口
缺点:方法签名绑定,需要一起变动;需要在格式上保持一致,解析成本高;需要额外的WDSL文件;需要需要根据WDSL生成一个代理
数据驱动
假设我们要设计一个RESTful风格的Web服务来管理“书籍”资源,资源路径:/books
| 请求方法 | URI | 操作 |
|---|---|---|
| GET | /books | 获取所有书籍 |
| GET | /books/{id} | 获取某一本书籍(通过ID) |
| POST | /books | 添加一本新书 |
| PUT | /books/{id} | 更新某一本书籍的信息 |
| DELETE | /books/{id} | 删除某一本书籍 |
实际上REST请求与实现完全无关,也就导致全用POST(没有做到纯数据驱动,方法仍然和业务逻辑绑定
Web服务的优缺点:
优点:跨平台;自定义(WSDL/REST);模块化;可以跨过防火墙(对特定端口控制通过性)
缺点:格式转换性能消耗(二进制转ASCII码);开发生产率低;安全性依赖于协议,且效率低
微服务Eureka
将后端系统拆分成多个互不相干的小组件,互相之间通过网络请求调用,虽然降低了性能(可以用Kafka的方式,先返回一个响应,然后再执行),但是提高了容灾能力,降低开发难度,方便维护,负载均衡,安全(可以只暴露Eureka,其他用内部IP)。
需要注册中心(Eureka)及gateway
具体的不写了(
无服务(函数式编程)(事件驱动),适用于一些简单的功能,还可以对多个函数进行组合。可以在调用时才启动,调用后回收。也可以相对智能地调度。
数据库
MySQL优化
索引优化
一般索引B树/B+树(一个节点的大小和page大小相近)。空间索引R树。哈希索引(内存表),反向索引(FULLTEXT)等
当表格scan开销比建立索引并维护还要快,就没有必要建索引。比如34个省
聚簇索引和数据在磁盘上存储的顺序一致,所以会读一次就是一整页,一个表只能有一个,默认主键上就是聚簇索引
如果建了多列索引,会浪费空间,不如设定一列自增索引
如果允许索引为空:浪费1bit;运行时一直做检查;树退化成链表
外键:数据中每列的访问频率有差异,比如价格和详情,然后就可以分表,通过外键关联;同样可以减少冗余数据
数据太长可以使用前N个字符建索引,并可以使用前缀压缩
MySQL利用索引搜索必须按照索引建立的顺序,比如先在第二列建索引,再在第一列建索引,那么如果搜索时限定条件只有第一列或先限定第一列再限定第二列,就无法使用索引
B树索引对Between和Like适配度高,但是Like不能以通配符开始
哈希索引对单值搜索性能好,不支持范围查找
优化数据大小及类型
数据段尽量设置成不为空,有额外的bit ;前缀压缩;索引尽量小,尽量高效;UUID在一些情况下性能比自增主键好(因为自增需要管理,自增也可以设置成不严格递增,就可以给多个管理者分配不同的数据段)
范式化:减少数据冗余(一般选3NF/BCNF)
- 第一范式:数据库总每一列都是不可再分的,每个表的字段都是最基本,不可再分的数据单位
- 第二范式:满足第一范式基础上,表中的非主属性的字段必须都完全依赖主键,不能部分依赖
- 第三范式:在满足第二范式的基础上,表中非主属性的字段不存在传递依赖关系
- BC范式:所有属性的字段不存在传递依赖关系
选择正确的数据类型(学号用int比string空间小)
8KB(一个page的一半)以下,使用varchar而不使用BLOB;以上使用BLOB
MySQL限制
数据库上限:无上限,只受限于操作系统目录限制
表的数量:无上限,只受限于操作系统目录限制
文件大小:无上限,只受限于操作系统目录限制
表的大小:1TB
列数:4096
列的大小(对于varchar,blob和text):65535Byte(64KB)(Blob和Text类型占用9和12byte,因为之存了指针;Varchar比实际指定的空间大一点;可以为空也需要额外的空间)
以InnoDB做引擎的表的每列最大大小是比page大小的一半略小(4KB、8KB等)
CHAR不可压缩,建表时超过page的一半就报错;VARCHAR可压缩,所以VARCHAR还会出现建表不报错但插入报错的情况,我们可以通过VARCHAR建一个大小接近64KB的表,但是插入数据到达page大小的一半时就会报错
表优化
当表体积变大,达到一个较大的大小时,可以重新构建(比如存储到一个page上减少空间浪费,减少磁盘碎片,重新构建更平衡的索引),很浪费时间,但是优化后效果更好
不用很长的唯一键,使用自增键
尽量用VARCHAR(可压缩,对于变长及可为空数据更好),不用CHAR(学号这种可以用char,是对齐的,而且可以用前缀压缩)
默认每条语句都在一个事务中执行,所以可以设置是否立刻提交;也可以设置多条语句使用一个事务,但是要避免大事务(回滚耗时长);缓存刷盘设置、选择性刷盘、大事务拆分;事务隔离级别设置;只读操作不上锁
在插入大量数据时,可以关闭唯一键检查(但是要人为保证),也可以设置唯一键不严格按顺序递增,这样mysql会为每个线程分配一块自增id;所以就不能通过最后一个id判断数据库的大小
索引创建的顺序,将最常用的放在第一个;根据查询需求建复合索引,注意索引顺序
磁盘IO
提高磁盘IO速度:
- 增加缓存(刷盘策略+Redis)
- 落盘策略:文件属性可以后落盘
- 设定刷盘间隔
- 不用机械硬盘,用SSD
- 设置存储介质(表放SSD,日志放机械;一个擅长随机读写,一个删除顺序读写)
- 换硬盘
主键类型和值不要修改
缓存设置
设置Buffer size时,默认Chunksize是128。指令需要指定Buffer size大小和实例数量,如果设8G,16个实例,实际buffer是8G;但如果改成9G,实际会分配10G,因为9G/16不是128M的整数倍。,实例最多是64个,Buffer size最少是1G
用内存表存储一些一般不会被修改的数据,默认是哈希表
预读:读取少的时候多读一些放在内存里
落盘线程数(小于实例数量),落盘阈值
暖启动:即使关机,也把部分缓存落盘,然后恢复缓存
MySQL备份
为什么要备份:容灾及升级迁移
物理备份:存储数据,可能遇到版本兼容性问题;适合大数据库
逻辑备份:存储SQL语句,可以在不同数据库中迁移;但速度慢
冷备份:停机备份;适合小数据库
暖备份:上写锁,可以读
热备份:会遇到数据一致性问题
全量备份:上面两种
增量备份:增量备份由MySQL自己实现,存储上一次全量备份至今的SQL语句,存储在多个bin-log文件里
快照备份:快照备份需要第三方工具,原理是存储上次全量备份后被修改的块
备份前必须刷盘
主从备份,恢复可以直接切换主从
四类问题及处理
- 操作系统崩溃:undo/redo恢复
- 断电:同上
- 文件系统崩溃:只能从备份恢复
- 磁盘坏了:同上。或者用显微镜手抄0/1(bushi
注意别把备份和数据库放一块盘上
多线程备份、文件压缩
恢复后如何比对
——哈希校验/默克尔树(原理也是哈希)
为什么bin-log文件不能并行读取
——因为按时间顺序,可能会出错
MySQL分区
将一张表分布在不同的服务器上,可以根据索引锁定到一个或几个服务器,分担服务器压力;可以在SQL语句里直接指定分区;还可以在分区内指定子分区
不支持垂直分区,只能水平分区
分区方法支持范围、离散值、指定列哈希、默认哈希等
使用范围分区时只能通过VALUES LESS THAN描述,注意最右表示成VALUES LESS THAN MAXVALUE,否则会有数据找不到分区(能保证数据有最大值也可以不建这个区);支持多列同时索引,但是最好要递增递减;范围只能建在各种整数类型及日期类型上,浮点数因为精度丢失不能作比较,TEXT\BLOB也不行
范围分区如果想要添加一个分区,只能在最后添加一个更大的值,不能尝试将前面的分区拆开。拆开分区有其他的操作。
对于范围分区:值为空的记录会放在第一个分区中而不是当作0
对于离散值分区:必须指定NULL的分区
对于哈希分区:NULL会当作0
为什么用一致性哈希/线性哈希:为了增删分区更方便
一致性哈希算法
- 假设一共有9个分区
- 先找出比9大的一个2的n次幂,值是16
- 将value与16-1按位与
- 如果得出的值大于9,则除2再分区;如果不大于9,直接落
Nosql-文本数据库 MongoDB
Nosql
Nosql——Not Only SQL
为什么需要Nosql?
——数据量过于大。使用Mysql会导致B树索引过大;随机IO性能降低;Mysql不擅长非结构化数据
Nosql数据库的特点:
PB级数据、一般只写一次、动态结构(可以增删数据段)、可扩展
MongoDB
MongoDB——humongous DB
特点:
- 文档型数据库:存储JSON格式
- 支持复杂索引:id作为唯一标识,可以在多个列上建立不同类型的索引(如地理空间索引,映射到地球经纬度)
- Auto-sharding自动分块
- 就地修改速度快
MongoDB有三个默认表
- admin用于做用户校验
- local没有副本,存储每台服务器的本地数据
- config用于记录分区等信息
对与关系型数据,性能及复杂语句支持不如MySQL
Sharding:将一个数据库分成多个shard,一个shard包含多个chunk。
如何确定数据存在哪里:使用router确定数据存储的位置,使用B树作为索引。
如何保证shard间数据量基本一致:默认按key的范围划分chunk,当某些chunk大小过大,则分裂成两个chunk,然后将chunk迁移,均匀分布在shard上
什么时候需要自动迁移
——数据访问量一致时,如果是新闻这种时效性强的数据,自动迁移可能导致sharding间负载不均衡
Nosql-图数据库 Neo4j
为什么需要图数据库
书店:查找用户买过什么书:user-order-orderitem-book,多次join,Mysql/MongoDB性能差,反向查询更复杂/无法实现
而图数据库无需扫描整个表,沿着边走即可
Neo4J 内部存储机制
- 存储文件:数据分块存储到不同文件中(节点、关系、标签、属性分别存储)。
- 关系存储的双向链表:节点与关系间使用双向链表连接,快速遍历关系网络。
- 支持分区,分成多个子图,并包含一定的冗余数据
- 节点的存储占用15byte:第一个位是一个标志位,是否有关联的边是否正在使用,然后(偏移量 1)是存储下一个边的ID关系,然后存储下一个属性的id,然后存储labels,最后存储其他的内容
- 边的存储占用34byte,第一个位是一个标志位,存储是否正在使用;之后存储这个关系的起始节点 是谁,终止节点是谁、关系的类型;然后存储第一个节点(边的起始节点)的前一个关系是谁,后 一个关系是谁,第二个节点的前一个关系是谁,后一个关系是谁,后面就是保留字段
- 是通过链表连起来的

Nosql-日志结构数据库
LSM-Tree,LevelDB,RocksDB
为什么需要日志结构数据库:
——新订单比老订单访问频率高,没有很好的方法支撑热点数据
只有追加写入,不存在删除和修改,通过分层,将热点数据放在内存及较高的树中。牺牲部分读取性能,适合于写多读少的场景。
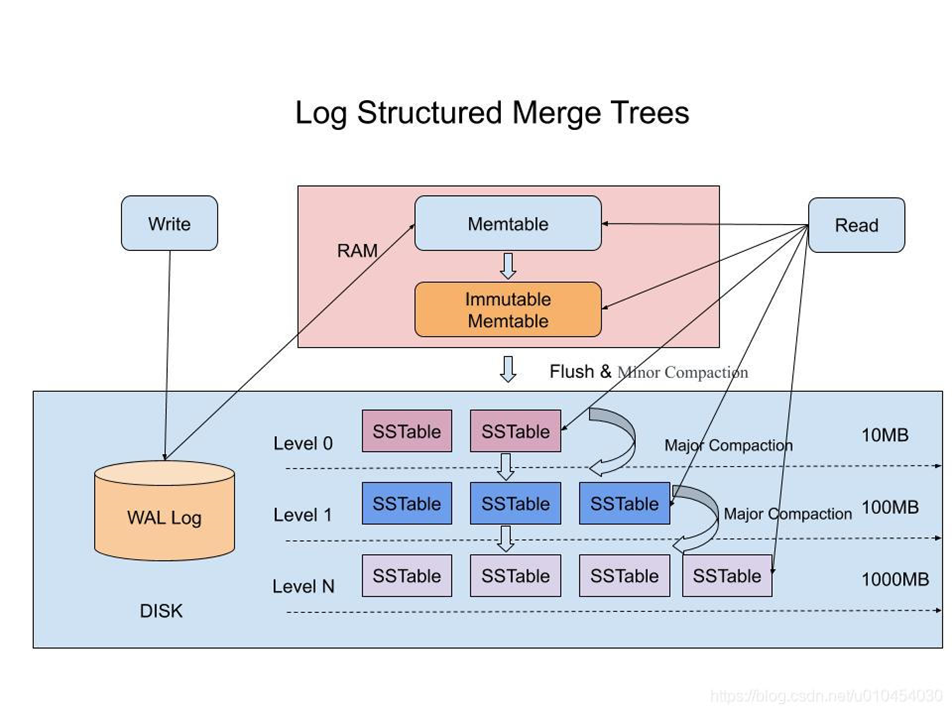
优化:对于“abc”“abd”等前缀一样的index,可以进行合并
问题:
- 写放大:写入时compaction导致一次写操作时间过多
- 读放大:读取时数据不存在/数据处于最底层
防止读放大写放大:层数过大的数据移动到其他数据库存储
HTAP混合事务分析处理
左边用“行存”,右边用“列存”。RocksDB两边都使用,但是造成了一定的空间浪费
能不能一边行存一边列存?
——首先会造成空间浪费,其次一致性维护难度大,再次性能受影响
Nosql-向量数据库
向量化:向量(embedding)由 AI 模型(如大型语言模型,LLM)生成,包含大量维度信息。向量的维度表示数据的特征,可用于捕获模式和关系。
用途:管理和存储高维特征数据,支持基于相似性的查询。
向量数据库的工作原理
核心:基于 近似最近邻(Approximate Nearest Neighbor, ANN) 搜索算法找到与查询向量最相似的向量。
相似度:余弦相似度、欧拉距离、曼哈顿距离等
主要算法:随机投影(Random Projection):将高维数据投影到低维空间,减少计算复杂度。
权衡:准确性 vs. 速度:向量数据库通常提供近似结果,需在性能和准确率之间做出取舍。
向量数据库的应用
典型工具:Pinecone 等。
场景:AI 推荐系统、图像/文本检索等。
Nosql-时序数据库 InfluxDB
时序数据库的特点:
- 只存在一段时间,过期数据可删去
- 格式简单
- 支持增量存储:不一定存储原始数据,可以存储差值(占用磁盘空间少,但是需要运算)
- 所有数据带有时间戳,前n位可能相同,可以使用前缀存储,也可以使用增量存储
InfluxDB的存储格式
- 时间戳
- tag(比如ServerA,ServerB)(参与索引)
- field key(比如CPU、GPU)(不参与索引)
- field value
tag和field根据实际需求确定,可以互相转换
InfluxDB使用类似于LSM-Tree的时间结构合并树TSM-Tree
批量写入批量读取,时间早的数据压缩存储
也可以shard分区,但是只能对未来时间分区
云数据库 GuassDB
分布式优化(部分)
- 多服务器,多机器,多线程并行执行
- 预编译执行
- 启发式规则查询优化
- 两地三中心:两个同城生产集群热备份(主从定期切换),一个异地容灾
- 分布式事务
- 节点内部计算等等
多租户
如何为多租户提供有细微差别的数据库
实现方式:
- 两个数据库×
- 两个互不相干的表×
- 共同数据放一个大表,然后为每个租户创建一个小表√
- 共同数据放一个大表,多出的字段转行存,记录“原表id-字段名-字段值”√
云原生
- 高精度授时
- 节点间数据传输优化
- 计算存储内存分离
- 节点级别日志回放(方便迁移及容灾)
- 数据预分区
数据湖 Hudi
数据仓库:从多种数据库上获取信息,做解析,使用时然后分析
数据湖:存储数据的原始格式,使用时按用户描述进行格式转换,然后进行分析
数据仓库和数据湖的区别是存储的数据是否结构化,与使用无关。数据仓库的数据是结构化的;数据湖是不管不顾结构化非结构化半结构化都能放进去
| 特点 | 数据仓库 | 数据湖 |
| 数据格式 | 使用ETL处理过的数据 | 原式数据 |
| 数据类型 | 尚未决定如何使用 | 直接使用 |
| 面向用户 | 数据科学 | 商业 |
| 可用性 | 高可用性,更新快 | 修改耗时高 |
支持流数据、批数据处理
集群
为什么需要集群:
——可靠性、可用性、可维护性(热更新)、可扩展性
集群部署-Nginx
代理和反向代理:
代理——几个用户用同一个ip访问后端
反向代理——几个后端用一个ip暴露给用户
为什么需要反向代理
——集群中状态需要一致,数据不一致;需要负载均衡;带session会话必须在用一台机器上执行
负载均衡的三种策略:
- Round-robin(weight):按比例分配,如3:1,则连续3个请求给server 1,1个请求给server 2
- IP hash:按用户的ip分配,一个ip访问的server一样(会话粘性)
- Least connected:给用户最少的server分配
故障转移:
- 请求级故障转移: 某节点无法服务时,将请求重定向到另一节点。
- 会话级故障转移: 如果会话状态在客户端和服务器间共享,需在新节点上重建状态。
都要求请求在不同程度上是幂等的
服务器响应还经过nginx吗?
——经过
Mysql InnoDB 集群
客户端与Mysql Router连接,Router与主数据库连接,主数据库与其他数据库做主从备份。写操作全部落到主服务器上,读请求在所有数据库上做负载均衡
云计算、边缘计算
云计算——计算资源像电一样即插即用
MapReduce
——将工作拆成多个互不影响的部分(map),全部结束后再合并到一起(reduce)
combine是本地结果合并,reduce是多个节点数据合并;有没有combine看业务需求,甚至可以没有reduce
GFS
——增加了可用性,但降低了一致性。读取性能好,写入性能差。
大文件分chunk存储在多个机器,有副本
使用大表(Big Table)将表与表间的关联去掉而合并成一张允许非结构化数据的表,然后分区存储
Hadoop
——提供公用接口、高可用性的分布式文件系统、MapReduce
边缘计算——计算无需在大型服务器中进行,在靠近客户端的边缘设备上计算。
计算任务需要在边缘设备和云服务器间调度
GraphQL
REST只能返回一整个对象,能否按需请求?
——GraphQL:一种新的查询语言
容器化部署-Docker
VM还要装系统,可是我连系统都不想装
不想要每次打包——挂载
不想每次启动很多容器——compose up
容器间通信——设置network
批数据并行处理-Hadoop
——分布式文件系统HDFS;任务调度MapReduce;分布式内存管理;分布式数据库HBase
HDFS建立在本机文件系统之上,将大文件切分后存储在本机文件系统中
使用MapReduce接口进行任务调度
框架:
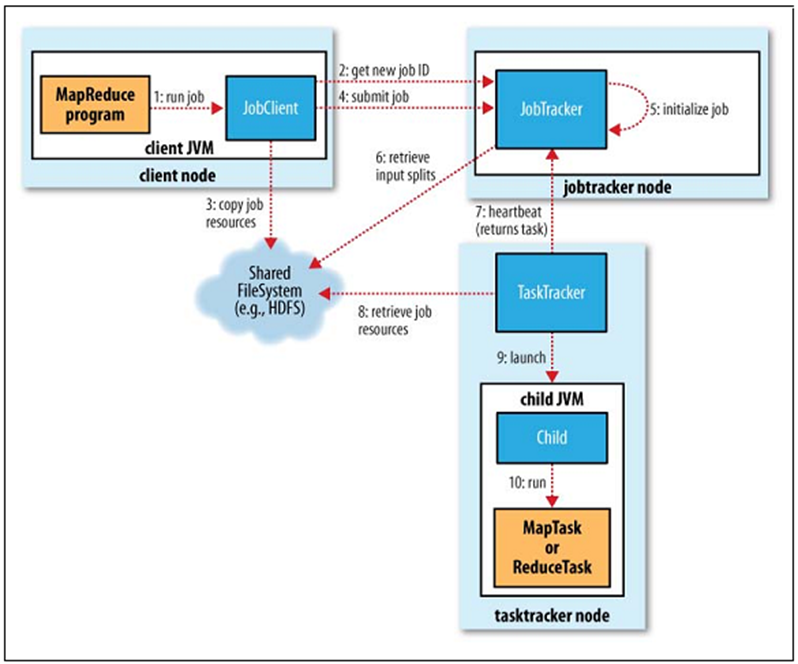
JobTracker是性能瓶颈
Shuffle+Sort的作用是在reduce前将数据排好序,让reducer能够快速定位,减少IO
Yarn进行了改进,在每个节点上增加了一个管理者,减少了崩溃导致的重做成本
MapReduce的问题:大量使用IO操作,能否全部放在内存里?
——Spark
批数据并行处理-Spark
RDD: 弹性分布式数据集,放在内存里,不能被更改,所以可以随意复用
懒调度:每执行到一个stage的末尾时,才开始真正执行这个stage的代码
使用cache()函数可以使内容保存在内存中,Spark会尽量保证其不会被换出到磁盘
块与块间存在宽依赖和窄依赖
窄依赖:父分区只被子分区中的一个分区使用
需要根据算法进行设计,比如使用哈希等策略,尽量使用窄依赖,有些宽依赖无法避免。宽依赖被当作懒执行时两个stage的分界。

懒执行的好处:如果Stage过大,会占用过大的内存,使用懒执行可以在执行时才占用内存。
spark还支持SQL语句
Spark流式处理的逻辑是划分小时间片,然后采用批式处理(微批处理)
流数据并行处理-Storm
类似于Spark,是真流式数据处理
可以将执行流转换成DAG计算图,然后并行
流式数据不会终止,进程一直运行,逻辑上和Spark类似
zookeeper是啥:监控每个server的状态,并进行管理
分布式文件系统-HDFS
适用于:极大的文件(小文件namenode占用内存,占不满datanode),一次写入多次读,尽量不要并行写(副本会出问题)
分成内存中的namenode和分布式存储上的datanode,datanode至少3个;namenode动态管理datanode中的副本,保证基本平衡
使用“机架感知”,确定副本放置的位置,不会将所有数据放在一个机架上。写入代价与容灾冲突。
同样负载均衡,读操作分散,写操作集中。
启动后一段时间不能操作,需要确定副本数量,运行时可以动态增加服务器
容错:
- datanode出错/网络问题:创建新的副本即可
- 数量不平衡:自动重新分配
- 数据传输错误:哈希校验码
- 镜像、日志文件出错:也有副本
分布式数据库-HBase
分布式,多版本(可以记录多个时间点数据的变化),面向列存;可以将几个列一起存储成“列族”(最好不要超过3个列)
列和行的交叉叫Cell
为什么是稀疏表:对于每一行,存储多个版本,时间戳递增,只需要保存和上一个时间点不同的值,如果一样则为空。
分布式数据仓库-Hive
Hive基于HDFS,存储原始文件(是结构化的),借助一定的中间格式(分为行存和列存-用于数据分析),使用SQL语句进行查询。加入数据时先不转成中间格式,只有在使用时才进行转换并检查格式(Schema on Read读入时结构化)
为什么要使用数据仓库而不用数据库:
Hive对文件格式不限,都可以存储,然后通过中间格式访问,甚至支持MySQL的表
Schema on Read/Write:
- Schema on Read可实现非常快速的初始加载,因为不必以数据库的内部格式将数据读取、解析和序列化到磁盘。
- Schema on Write架构可以提高查询时间性能,因为数据库可以对列编制索引并对数据执行压缩。
分布式并行处理框架-Flink
真流式处理,与storm的区别是实现方式不同,各有所长
支持有状态数据的流式处理框架。有状态:处理当前数据需要用到先前数据的处理结果。状态数据存储在自己的内存和或硬盘中,周期性在主机上做增量式的快照
因为数据可能是乱序来的,所以需要先落盘,留出一段冗余,然后再处理
提供三个层,可以在不同层级控制:高层使用SQL语句管理数据,中层管理流数据,底层管理单独的事件
“水位线”:数据可能是乱序来的,每个处理流程记录一个值,表示比时间这个值小的数据都已经被处理,目的是防止多个流数据混乱
人工智能
神经网络
Keras是一个前端,支持三个后端,包括tensorflow和pytorch
神经元:神经元接受多个输入,经过加权计算,产生一个输出
神经网络:多个神经元组成一层,多层产生神经网络。分为输入层,隐藏层,输出层
如果是分类问题,理想状态下我们希望输出层只有一个为1,其余为0
我们需要根据问题复杂度设计隐藏层的大小,不匹配会导致过拟合或欠拟合
Dense:全连接层,两层间任意两个神经元间有连接
设置批量batch的原因:并行计算一个和多个速度一样;原理是执行完每个batch进行一些修正,执行完多个再修正效果更好
放缩到0-1的原因:防止越界导致过大的影响,放缩后即使越界也不会overflow
激活函数为什么必须是非线性的:因为多个线性函数的组合仍是线性函数
Dropout可以设置忽略一定量的数据,防止神经网络只关注局部特征
卷积神经网络CNN
目标:通过卷积提取局部的特征
例:通过卷积提取边缘
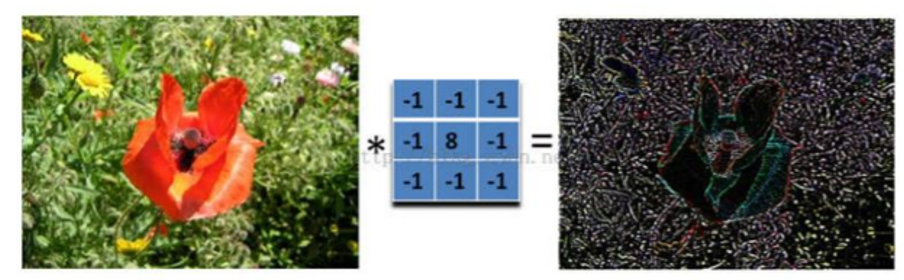
假设图片过于大,我们可以使用“池化”,即设置卷积的步幅,使卷积后的图片变小
还可以增加“深度”,使用多个卷积核,提取不同的特征。
模型的大小应该和问题的复杂度相匹配
自然语言处理
如何将一句话转成数值
——一个词语对应一个多维向量/BOW:只记录一句话中词语出现的次数,不记录顺序
假设我们有一个语料库,我们首先需要用字典进行词语切分,再产生一个新字典(包含词语及其id),再进行过滤,去除极常用和极不常用的词,再添加短语,得到最后字典。然后通过一维卷积,提取多个单词间的关系,得到分类结果
TextCNN和SimpleCNN的区别:SimpleCNN的卷积长度是固定的,而TextCNN将长短卷积核得到的结果进行拼接,可以提取不同长度上的特征
循环神经网络RNN
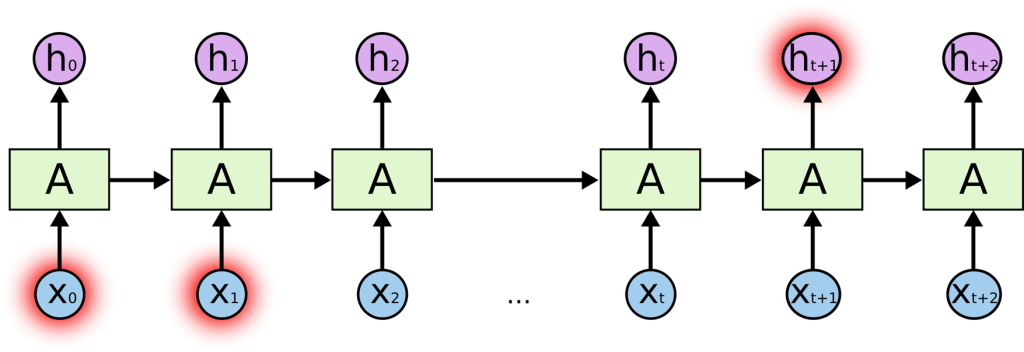
SimpleRNN:基本想法:使用前面得到的结果,产生后面的输出。坏处是不能并行。
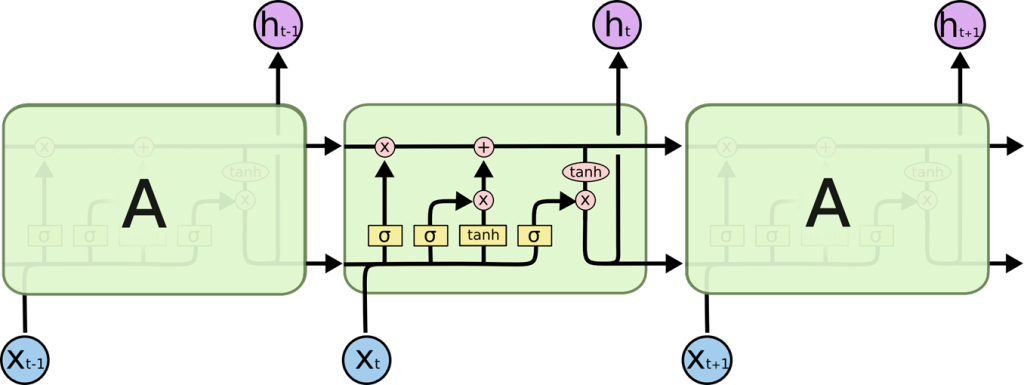
LSTM:但是有时我们不需要把很前面的结果全部传递到后面,所以可以随机忽略前面的结果,也就得到了LSTM长短时记忆模型
ChatGPT
“Just adding one word at a time”
假设我们通过训练,得到了下一个词的不同可能性,以及对应的概率,我们如何保证每人得到的值不同?
——设置一个温度,温度越高,越有可能不选择概率最高的词语。
概率是如何得到的?
假设我们得到了关于“cat”的语料库,首先我们统计每个字母出现的次数,然后让a模型产生一些“单词”,显然这个单词并不存在于字典里,所以我们还需要关注字母与字母间的关系,比如q后面经常出现u,再进行训练,就可以产生一些正确的单词。
产生单词后,我们在词和词之间做同样的训练,但是词语的个数远大于字符数,所以需要进行降维处理。
Transformer
transformer的产生:
在CNN,中我们用小卷积核提取小范围特征,用多层卷积提取长范围特征,问题是不能看出词的顺序,而且很难反应前面词对后面词的影响;于是产生RNN及LSTM,通过将上一次输入变成下一次的输出,这样可以保持词与词之间的关系,缺点是不能并行执行。于是产生Transformer
Transformer架构:
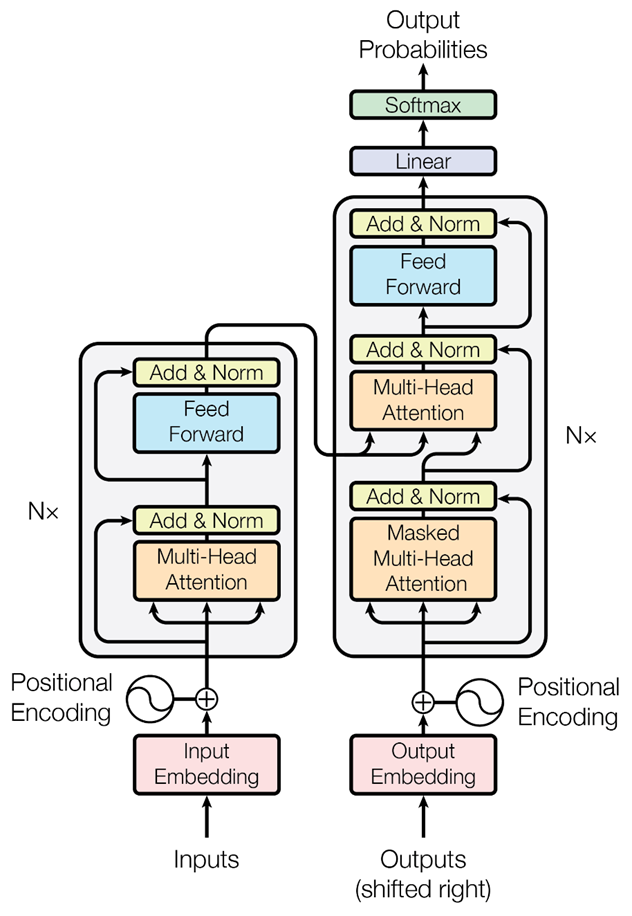
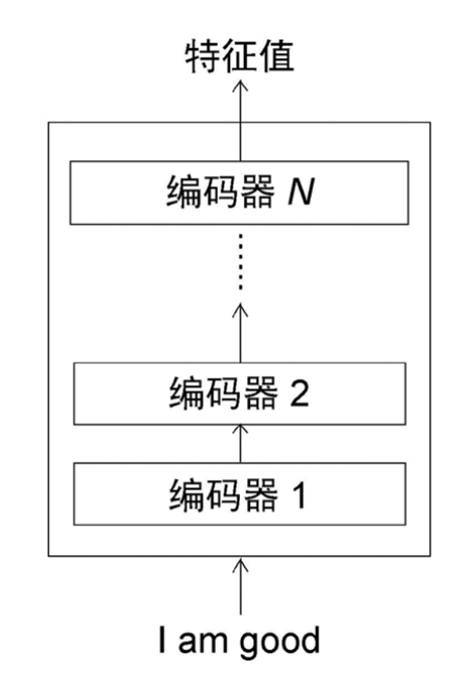
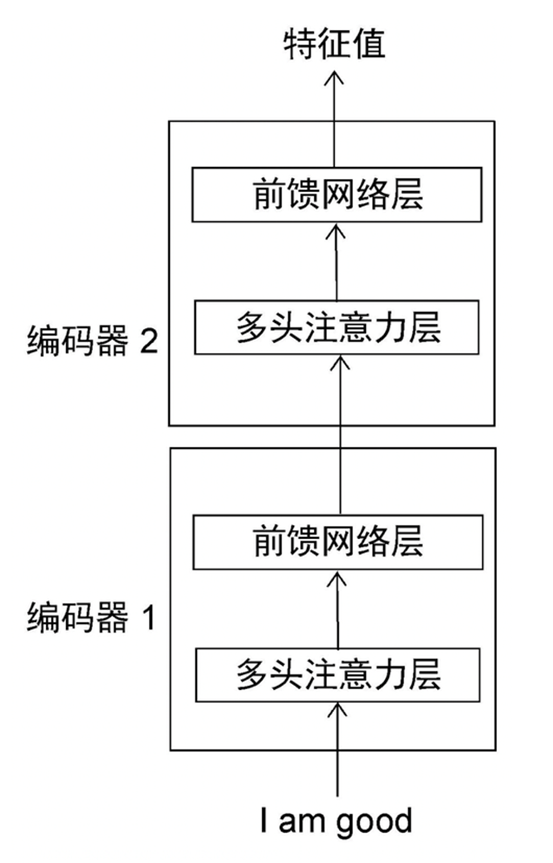
左侧为编码器(输入一句话,输出一串特征),右侧为解码器(用特征产生结果),另外需要多个编码器嵌套
为什么需要多头记忆力:自然语言有歧义。注意力需要通过查询矩阵Q、键矩阵K、值矩阵V计算,得到一个注意力矩阵
为了反应词语顺序对句子的影响,可以使用位置编码
相较于LSTM的优点:编码器可以并行计算