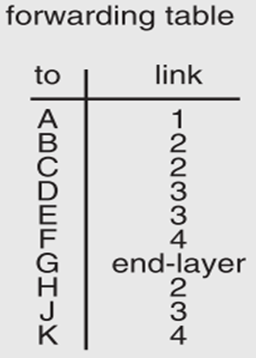
File System & Distribute File System
——Here we start with File System.
Inode_based File System
——I assume you did your lab1 by yourself.
L1: Block Layer

Super Block 存储Blocksize、剩余空间等信息
L2: File layer
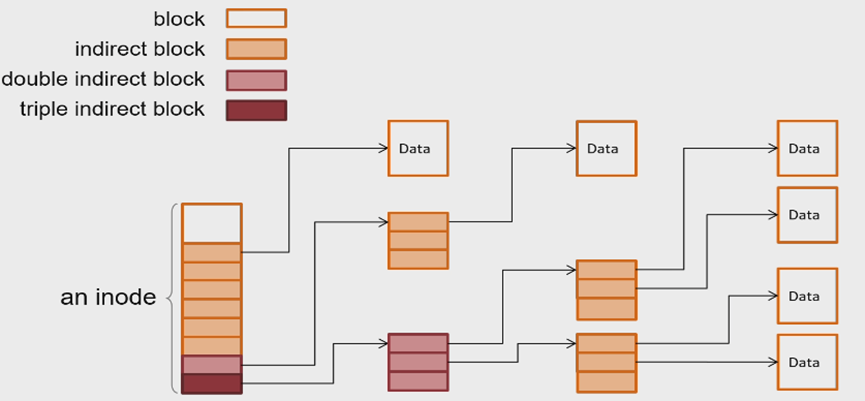

L3: inode Number Layer

L4: File Name Layer

L5: Path Name Layer
文件目录(或者说文件夹)也以File的形式存储,data为下一级目录/文件的inode
在此层实现了“link”(或者是hard-link),一个文件(注意不是文件夹)可以有多个名字,需要使用reference count防止删除时出现问题
L6: Absolute Path Name Layer
文件系统的入口:根目录:A well-known name: ‘/’ ;Both ‘/.’ and ‘/..’ are linked to ‘/’
——We take a break here. See what we have achieve.
How to find ./programs/pong.c ⬇
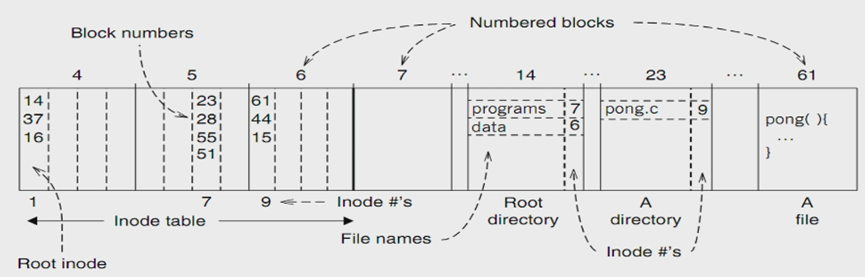
L7: Symbolic Link Layer
我们通过symbolic link (soft link)实现了类似于快捷方式的操作,他指向一个文件,文件的值是一个目录的名字。
hard-link与soft-link对比:
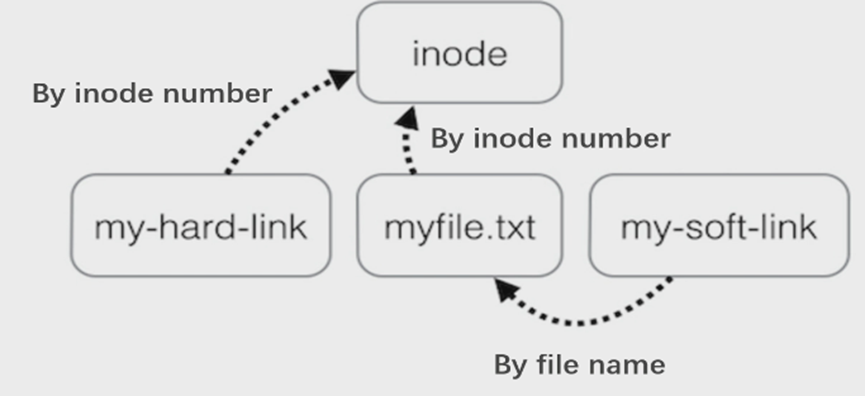
hard-link与soft-link的区别:
- 如上图,指向不一样
- 不能为不存在的文件创建一个hardlink,因为inode不存在
- Symboliclink 是可以指向目录的,而hardlink 除了.和..是不能指向目录的
File System API
——I find this part kind of boring and hopefully not be used in exam.
open() vs. fopen()
- open()是系统调用,返回FILE*;fopen()是C++实现,返回fd
- fopen()可能更快,因为实现了buffer
File metadata –inode struct

打开文件时,匹配userid、groupid、权限,然后更新last access time,最后返回一个fd
File Descriptor(fd)
Why fd rather than inode:为了安全,禁止用户进入内核,绕过权限检查打开文件。
File Cursor
即下图中File pos
打开一个文件两次:
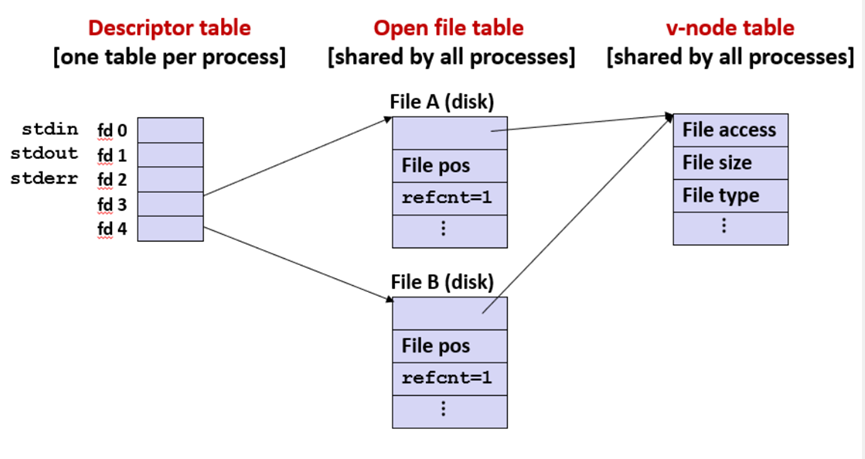
fork子进程:

更多参见SE2301
非inode_based file system:FAT32用链表
Remote Procedure Call(RPC)
使用网络请求实现Read()和Write()
别的没看懂,好像没什么大用
Distribute File System
Network File System(NFS)
定义:
- NFS 是什么:NFS 是一种分布式文件系统协议,允许客户端通过网络访问远程服务器上的文件,像操作本地文件一样使用这些文件。
- 基本原理:客户端将远程服务器的文件系统“挂载”(mount)到本地,通过网络进行文件的读取、写入等操作。
- 无状态设计:NFS 服务器不保留客户端的状态信息,每次请求独立处理,服务器崩溃后无需恢复客户端状态。
- 缓存机制:为了提高性能,客户端可以缓存文件数据,减少访问服务器的次数。
问题:
- 容量限制:只能依赖单个服务器上的磁盘,容量有限。
- 可靠性问题:如果服务器崩溃,远程文件将无法访问。
- 性能问题:文件的性能受限于单个文件的操作以及单一的网络带宽。
Google File System(GFS)
——Really boring, but in exam last year.
GFS(Google File System)是专为分布式大规模数据存储设计的文件系统,解决了在传统文件系统中难以应对的容量、可靠性和性能问题。其实现方式可以分为以下几个关键点:
总体实现
- 1. 分布式架构 GFS 采用分布式文件系统架构。文件被分割成多个较大的数据块(通常为64 MB),每个块存储在不同的服务器(称为Chunkserver)上。这样,通过将文件分布到多个服务器,可以大幅提升系统的存储容量和性能,轻松扩展整个集群的容量。
- 2. 主节点管理 GFS 使用一个主节点(Master node)来管理文件与块(Chunk)之间的映射关系。主节点存储了文件目录和每个文件块的位置,客户端通过与主节点的交互找到所需的文件块后,直接与 Chunkserver 进行数据交换。这种设计简化了文件的查找和管理。
- 3. 多副本机制 为了提高可靠性,每个文件块在不同的 Chunkserver 上有多个副本(通常为3个)。当一个服务器发生故障时,客户端可以从其他副本中获取数据,保证文件不会因为单点故障而丢失。这种副本机制让 GFS 在面对硬件故障时依然能够保持高可用性。
- 4. 并行读写 GFS 支持并行读写操作,多个客户端可以同时从不同的 Chunkserver 读取文件块。通过并行化读写,GFS 大大提高了文件访问的效率,尤其在处理大文件时,能够充分利用网络带宽和服务器的计算能力。
- 5. 松散一致性模型 GFS 采用了一种
松散一致性模型,允许在一定时间内数据处于不一致状态。这种模型通过主节点协调写操作,确保数据最终能够在多个副本之间达成一致性。虽然放宽了一部分一致性要求,但这种设计能够提高系统的写入性能。 - 6. 容错和恢复机制 GFS 具有很强的容错能力,系统会定期检测 Chunkserver 的状态,如果发现某个副本丢失或服务器故障,主节点会自动指派其他服务器重新创建该副本,保证数据的完整性和可用性。
具体过程
阶段 1:发送数据
- 传输数据,但不写入文件。
- 客户端会得到一个副本列表,标识主副本(Primary)和次级副本(Secondary)。
- 客户端将数据写入最近的副本。
- 管道式转发:副本服务器通过流水线方式转发数据。(可以减小单个传输数据压力)
- 块服务器将数据存储在缓存中(内存中)。

阶段 2:写入数据
- 将数据添加到文件中(提交)。
- 客户端等待所有副本确认已经收到数据。
- 客户端向主副本(Primary)发送写请求。
- 主副本(Primary)负责序列化写操作(先应用写操作,然后转发给其他副本)。
- 当所有确认(ack)都收到后,主副本向客户端发送确认。
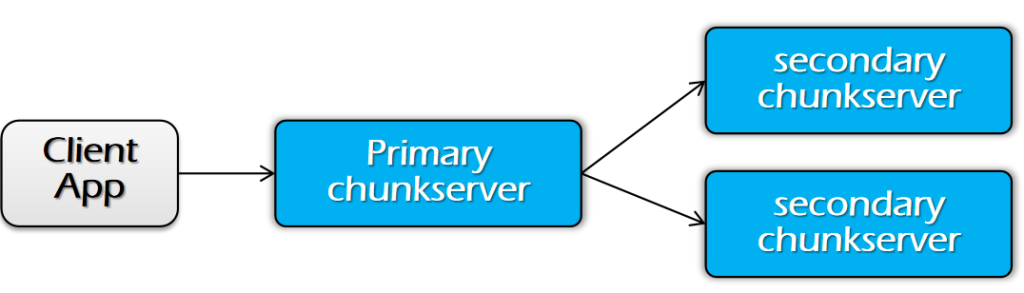
总结:
数据流(阶段 1)和控制流(阶段 2)是不同的
- 数据流(Phase 1)
- 路径:客户端(Client)→ 块服务器(Chunkserver)→ 块服务器(Chunkserver)→ …(通过流水线方式转发数据)
- 顺序:数据流的顺序无关紧要,数据可以在不同的副本间自由传递。
- 控制流(Phase 2)
- 路径:客户端(Client)→ 主副本(Primary)→ 所有次级副本(Secondaries)
- 顺序:必须保持顺序,尤其是在多个客户端同时进行写操作时,主副本负责保证写操作的顺序。
Hadoop Distributed File System(HDFS)
—–another popular (open-source) DFS, just like GFS
All above are not perfect.
Key-value storage(KVS)
——a system with a simpler API
API:
GET(K,V), SCAN(K,V)
UPDATE(K,V), INSERT(K,V), DELETE(K,V)
API与应用级接口对应:
- Get(K) -> V:类似于文件的 OPEN(…) + READ(…) 操作。
- Insert(K, V):类似于 CREATE(…) + WRITE(…),用于创建新文件并写入内容。
- Delete(K, V):类似于 DELETE(…),用于删除文件。
- Update(K, V):类似于 OPEN(…) + WRITE(…),用于更新文件内容。
这种映射使得KVS可以与FS进行类比,实现简化的文件操作与存储管理
各种实现方式。
Log-structured file (append only,所有的修改都只是追加,不产生修改)→
Log + in-memory hash index (内存中保留一个哈希映射)→
Log + on-disk hash
- Linked-list based hash index→
- Cuckoo hashing
LSM-Tree
——Boring part finally end, but difficult part start.
Atomicity: All-or-Nothing and Before-or-After
Consistency
——We need to ensure that everyone sees the same value.
Four Consistency models
——From Strict consistency to Eventual consistency, choose according to your requirements.
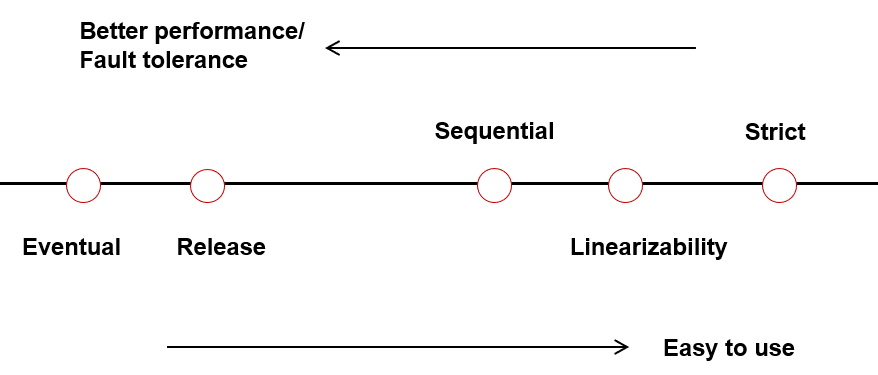
1.strict consistency 全局发起顺序(严格一致性)
定义:
- All the concurrent execution is equivalent to a serial execution(等价于一个串行执行)
- The order of each op matches the global wall clock time(操作顺序与全局时钟匹配)
- 即:执行顺序与事务发起时间完全一致(谁先发起谁先执行)。
优点:
- The strongest consistency model for single value operations(适用于单值运算的最强一致性模型)
- Fallback to a single thread, executing each operations one by one(回退到单个线程,逐个执行每个操作)
缺点:在分布式系统中不切实际,出于性能考虑,以及不存在全局时钟
2. sequential consistency每个进程的发起/完成顺序(顺序一致性 )
定义:
- All the concurrent execution is equivalent to a serial execution(等价于一个串行执行)
- The order of each op matches per-process issuing/completion order(操作顺序与每个进程的发起/完成时间匹配)
- 即:每个进程的各个操作间顺序正确即可,全局无所谓,不同进程看到的系统状态不一致
3. linearizability全局“完成-发起”顺序(线性化 )
定义:
- All the concurrent execution is equivalent to a serial execution(等价于一个串行执行)
- The order of each op matches “completion-to-issuing”(操作顺序与“完成-发布”匹配)
- 即:操作完成后,结果对于全局可见(或者说不能出现put之后get为空)
Differences between sequential & linearizability:
- 都等价于一个串行执行
- But linearizability requires that the effects of the completion of an operation be visible to all operations that begin after the global physical time of the completion of that operation(操作完成后,结果对于全局可见)
4. Eventual consistency(最终一致性)
定义:
- 所有服务器最终都会收到所有写操作,拥有相同写操作的服务器将有一致的数据内容。
- 因此,如果数据没有新的更新操作,最终所有的访问都会返回最后一次更新的值。
实现:
- Read:返回服务器上的最新本地副本数据
- Write:先在本地执行并直接返回,写入的数据会在后台传播到所有服务器
Eventual consistency与Linearizability对比:
| 特性 | Linearizability | Eventual Consistency |
| 冲突处理方式 | 悲观的冲突处理 | 乐观的冲突处理 |
| 冲突写入的常见性 | 冲突写入是常见情况 | 冲突写入是罕见情况 |
| 更新生效时间 | 更新在序列化之前不会生效 | 允许更新发生,稍后再对数据进行序列化 |
| 最终目标 | 数据需要在多个设备之间保持一致 | 最终目标相同:数据在多个设备之间保持一致 |
Eventual consistency的问题:
- 写-写冲突。当多个服务器在不知道彼此的情况下同时更新相同的数据时,会发生这种情况。
- Loss of causality 因果关系损失(B对A的依赖可能会丢失)
- 解决方案:Lamport clock/Vector clock
Lamport clock & Vector clock
Lamport clock(全序,即对任意两个事件有先后关系)
定义:
- 每个服务器维护一个时钟T。
- 随着实际时间的推移,T递增,例如每秒增加1。
- 如果从其他服务器看到T’,则更新T为 T = Max(T, T’ + 1)。
问题及解决方案:
- 通过添加额外的顺序来解决时间戳相同问题,比如使用 <逻辑时间, 节点ID>,这样可以保证全序保持因果关系。
- 全序使无关的事务间有了先后关系,所以偏序更合适,因此产生了Vector clock
Vector clock(偏序)
为每组互相没有关系的数据维护一个Lamport时钟,所有时钟存储为一个向量,值的更新遵循Lamport Clock
Lamport 与 Vector 对比
| 特性 | Lamport 时钟 | Vector时钟 |
| 因果关系捕获 | 捕获因果关系 | 捕获因果关系 |
| 顺序类型 | 全序(Total Order) | 偏序(Partial Order) |
| 使用场景 | 适用于大多数场景 | 用于需要更严格因果关系的场景 |
| 事件排序 | 能够为所有事件提供顺序 | 提供部分事件的因果顺序 |
| 存储需求 | 节省空间,仅需存储单个时间戳 | 需要更多存储空间,每个节点一个条目 |
| 复杂性 | 较低 | 较高 |
Final Problem :truncate log
为什么要截断日志:为了恢复时无需使用全部日志,节约空间,我们需要确定哪些更新是稳定的。
两种方法:
- Centralized approach:use the primary server to determine which ops can be turned into stable.(使用Primary server决定)
- De- Centralized approach:no primary server, the server decides whether to make the ops stable based on the Lamport Clock it received from other servers.(每个server根据自己的Lamport clock决定)
| Approach | Server1’s all writes | Server 1’s information on others | Primary’s response that Server 1 received | Server1’s stable writes |
| De- Centralized approach | <11, srv1> <12, srv2> <14, srv1> | Server 0’s Lamport clock: 12 Server 1’s Lamport clock: 13 Server 2’s Lamport clock: 15 | (no need to fill) | <11, srv1> <12, srv2> |
| Centralized approach | <-, 11, srv1> <-, 12, srv2> <-, 14, srv1> | (no need to fill) | <1, 11, srv1> <2, 12, srv2> <3, 13, srv0> <4, 14, srv1> | <1, 11, srv1> <2, 12, srv2> <3, 13, srv0> <4, 14, srv1> |
——Finally we achieve consistency, but network failure totally destroy it. We need All-or-nothing & Before-or-after. It’s kind of difficult, so let’s start from single machine with multi-process.
实现All-or-Nothing
——基于shadow copy & Journaling/(logging + checkpoint),实现事务“全做/不做”
shadow copy
实现:
- 创建文件副本,在副本上修改(注意是整个文件)
- Rename(将副本变为新的原文件,需要文件系统原子操作)
- 删除原文件
如何实现文件系统原子操作:Journaling
Journaling
实际上就是lab2实现方式
实现:
- 记录更改到日志(Journal)。
- 提交日志。
- 执行更新。
发生崩溃后的处理:
- 提交前崩溃:没有数据被更改,丢弃日志。
- 提交后崩溃:日志完整,重做日志中的更改。
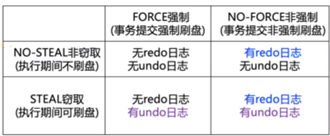
问题及解决:所有内容都需要写入磁盘两次,大文件会出问题;解决:Logging for atomicity
Logging for atomicity
与Journaling的区别:比Journaling层次更高,不局限于文件系统,由用户自行决定如何记录(比如记录操作,所以可以简化)
两种实现方式:记录用户操作/对值的修改
实现方式:redo log/undo log/redo-undo log
Redo logging记录修改后的值,undo logging记录修改前的值(更多参见SE3353)
CheckPoint
CheckPoint机制:
- 等到没有action在进行
- 将checkpoint写入日志,包括所有正在运行的事务,以及对应的日志
- Flush all page cache
- 丢弃除checkpoint 记录之外的所有日志记录(去掉以前的日志)
如何使用CKPT恢复:(以下均指在“crash”时刻)
- 对于ongoing TX:undo its updates based on the log entries.
- 对于committed TX:redo its updates based on the log entries.
- 对于crashed TX:undo its updates based on the log in both CKPT & log entries.
实现Before-or-after(Serializability)
——为了防止出现race condition问题(多个人对一个值同时加,且没有注意到另一个人修改),我们需要:“一组读/写操作是原子的”
简单解决方案:全局锁/2PL
全局锁:开始时拿全部锁,结束时统一释放。
Two-phase locking (2PL)(访问前拿锁,最后一次使用结束后释放)
问题:中间结果不一定对,尽管结果正确
三种Serializability模型:
1.Final-state serializability:如果一个调度的最终写入状态与某个串行调度的最终状态相同,那么这个调度是Final-state serializability的。
2.Conflict serializability(最常用)
定义:如果一个调度的冲突顺序(即冲突操作发生的顺序)与某个串行调度中的冲突顺序相同,那么这个调度是Conflict serializability的。
Conflict的定义:
- 它们对同一数据对象进行操作
- 其中至少有一个是写的
- 它们属于不同的TX
冲突图:

以上的冲突图写作T1->T2
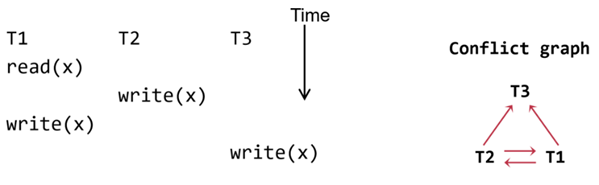
一个调度是Conflict serializability的,当且仅当:它的冲突图是无环的。
3.View serializability(几乎没人用):如果一个调度的最终写入状态以及中间的读取操作与某个串行调度相同,那么这个调度是视图可串行化的。(显然也满足Final-state serializability)
结论:2PL可生成Conflict serializability的调度,前提是使用锁妥善解决冲突。
问题:2PL可能产生幻读(范围查找时出现)、死锁问题。
OCC (Optimistic Concurrency Control) 乐观并发控制
想法:执行事务without lock。TX提交前检查结果,如果违反serializability, 则aborts / retries
实现:
- 第一阶段:事务开始时,在本地进行数据读取和写入的暂存,不对实际数据库做改动,减少了锁的使用。Read:将读取的数据加入“读取集”;Write:将写入的数暂存到“写入集”
- 第二阶段:在事务提交之前,进入关键区进行检查,确保读取的数据没有被其他事务修改,从而保证一致性。如果检测到冲突,则回滚该事务。
- 第三阶段:根据验证结果,决定提交或中止事务。如果通过验证,将暂存的数据写入数据库,否则放弃该事务。
- 第2&3阶段必须在critical section(关键区)内进行,即atomic(仅包含验证逻辑,执行时间通常很短)。因此关键区可用全局锁/2PL实现
优势:减少锁操作,更适合读取多于写入的场景,因为它仅在提交时才需要验证冲突,大大降低了锁的开销。相比之下,2PL 需要每次获取和释放锁,带来额外的性能开销。
锁的实现:使用硬件支持的原子性操作(硬件原语Hardware primitive提供了保障操作原子性(不可分割)的机制)
- Compare-and-swap (on SPARC)
- Compare-and-exchange (on x86):CompareAndSwap(int *ptr,int expected,int new):如果ptr的值与expected相同,则将ptr的值修改为new。返回值均为ptr的原值。
- 锁前缀Lock prefix 以确保在内存地址上以原子方式执行指令
问题:
- 某些满足serializability的情况被abort
- 争抢发生很多的情况下,会持续abort,进行但没有进展
OCC的应用:
HTM(Hardware Transactional Memory),在汇编层面由CPU保证before-or-after,英特尔实现RTM时使用了OCC。优点是编程简单,缺点是不能保证事务成功执行,可能因为资源冲突、硬件限制或其他原因被中止,需要编写备用逻辑处理这种情况。
MVCC (multi-versioning concurrency control) 多版本并发控制
——使用MV(多版本)优化OCC→MVCC
初步想法:
- Read:开始时从统一快照中读取
- Write:1.添加一个新版本而非覆盖2.版本号约等于事务提交时间
要求:
- counter必须反映事务的顺序执行顺序。
- 例如,如果事务 T1 在 T2 之前完成,则 T1 应有较小的开始和提交时间戳。
- 对于只读事务,不需要counter,但counter对写操作非常关键。
实现:全局计数器(可以不用,但是很有挑战性)
- 使用原子操作(FAA)获取事务的开始和提交时间。
实现:
- 获取开始时间:在事务开始时获取一个时间戳,表示读取操作开始的时间。
- 阶段1:并发的本地处理:
- 从最接近开始时间的快照中读取数据,以确保一致性。
- 将写操作缓冲到写集合中,而不是立即应用到数据库中。
- 获取提交时间:在进入提交阶段之前,获取提交时间。
- 阶段2:在关键区中提交结果:
- 将写集合中的更改提交到数据库中,并标记为提交时间的版本。
- 与传统OCC不同,这里不需要验证步骤,因为使用了多版本机制,避免了读写冲突。
问题及解决方案:
- 目前MVCC保证了读取无竞争,但不保证写,因此需要:在提交期间,检查另一个 TX 是否在本 TX 的开始时间之后安装了新快照
- Write skew anomaly(写入扭曲异常)
- 定义:1.两个事务同时读取共享的数据库状态,并基于读取的值做出决策。2.这两个事务分别进行写操作。3.最终的结果可能违反数据库中的一致性约束(通常是基于应用逻辑的约束),尽管每个事务在其视角下看起来是正确的
- 解决:1.在读写事务中退回到OCC,仅read-only事务使用MVCC2.忽略读写验证(Usually in practice),等价于快照隔离(Snapshot isolation)

Multi-site transaction & Multi-site atomicity
——You remember we need atomicity in a DFS rather than a FS right?
All-or-nothing使用TX+logging即可实现,Before-or-after?
实现Before-or-after
目标:all sites either all commits or all aborts
实现方法:Two-phase Commit (2PC)
- 第一阶段:准备/投票
- 延迟低层 TX 的提交
- 低层TX要么中止,要么暂定(Tentative)提交
- 高层事务评估低层情况
- 第二阶段:
- 高层决定低层TX是提交还是中止
- 高层还协调低层 TX 的提交
还需对logging的写入规则进行修改:
- 低层事务
- Redo-undo:正常
- Commit log entry转为Tentative commit log entry (PREPARED)其中包括对高层事务的引用。如果本地崩溃,询问高层是否提交
- 高层事务
- 将“PREPARED”log 作为高层事务的提交
改进:
- 2PL:每个低层 TX 都无法释放其锁,直到高层 TX 决定提交
- OCC:验证和提交阶段由高层完成
The CAP theorem: 2 out of 3
- 一致性Consistency (all nodes see the same data at the same time)
- 可用性Availability (a guarantee that every request receives a response about whether it succeeded or failed)
- 分区容错性Partition tolerance (the system continues to operate despite arbitrary message loss or failure of part of the system)(一般总是成立,所以CP/AP)
而2PC仅实现了Consistency,需要replication(副本)来实现高可用性(high availability)
实现Linearizability
——We can finally implement consistency now! Eventual consistency is unacceptable in DFS,then let’s try Linerizability!
目标:single-copy consistency(多副本等价于单一副本)
Replicated State Machines (RSM)副本状态机
抽象模型:
- 拥有相同的初始状态
- 所有副本以同样的顺序接受同样的输入操作
- 所有操作均有确定性(无随机数等等)
问题:网络问题无法保证相同的顺序
解决:使用primary-backup mechanism
- 使用view server来保证仅有一个机器作为primary
- 如果原有的primary挂掉,重新分配primary
Primary的职责:
- 在对所有备份更新以后,最后再ACKing the coordinator
- 决定所有事务的顺序
- 决定所有的不确定值(随机数等)
但是仍有网络问题(比如view server挂掉/仅vs 与primary无法通信),解决方案:Use Paxos as view server
Paxos
Single Decree Paxos
——One hundred people argue, and all of them remember one same value in the end.
角色:
- client:发起请求
- proposer:接受请求,发起一个提案(propose),尝试让提案被大多数acceptor接受
- acceptor:存储提案编号和提案值,决定是否接受某个提案,
- learner:需要得到提案的结果
实现:
- Phase 0:client给一个proposer发送请求
- Phase 1:
- Proposer:生成第N号提案(N比他所见的任何编号更大),并发给大多数acceptor
- Acceptor:如果N比自己见过的最大号大,则返回自己见过的最大号提案的编号以及内容,并承诺会拒绝小于N的所有提案;若N比自己见过的最大号小,则忽略(拒绝)
- Phase 2:
- Proposer:如果接收到大多数的promise,则设置第N号提案的值为V(如果任何acceptor返回了一个Vi,则将V设置为提案号最大的Vi),并发给所有acceptor
- Acceptor:检查N是否仍然是见过的最大号,如果是,则将V记录下来,告诉proposer和learner自己已经accept;否则忽略
- Phase 3:Learner:收集Acceptor的accept消息,记录V到数据库或发送给client
Multi-Paxos
——Just when we finish argue, fuckin’ network failure enforces us to argue a new value.
Single Decree Paxos的问题:只能同意一个值,不能更新。
解决方案:通过Append log的方式,每个日志条目(log entry)都使用一组paxos机器(of course logical)决定其值。
Example:
初始状态:三台机器已对log entry为0、1、2的日志的值达成协议,现在S1想将想添加一条值为yyy的日志。
过程:
- S1发起paxos请求,希望将log entry为3的日志值设为yyy
- 若S2/S3均未使用此日志,则返回promise,S1再发送Accept,设置所有机器的日志值。
- 若S2/S3中有人使用此日志,则返回之前设定的值,S1会将此值传播给所有机器
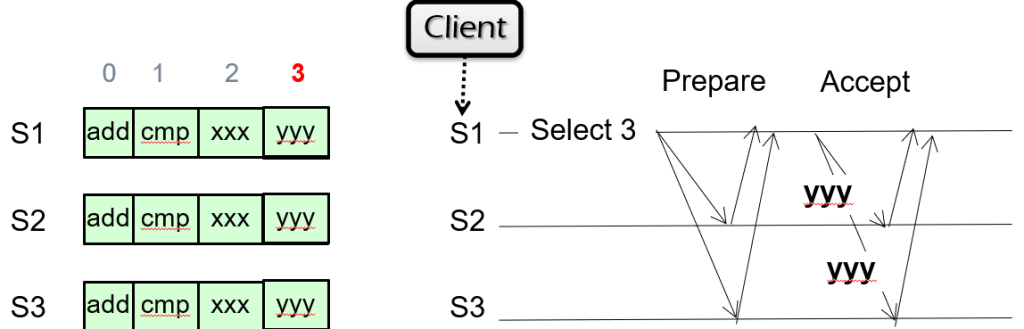
优化:同时设定多个值时,可以同时Select and Prepare 3和4,再发送两轮Accept
——Paxos is good theoretically, but hard to implement.
Raft
OverView
- Leader election
- Only one Leader
- 发现网络问题,重新选举
- Log replication (normal operation)
- Leader接收客户请求,添加log
- Leader将自己的log复制给其他server(或覆盖)
- Safety
- 保证数据一致性
- 仅有日志足够新的服务器才能成为leader
三个角色
- Leader: 响应用户请求,复制Follower的日志(active)。每时每刻只能有一个Leader
- Follower: 只对发过来的RPC请求进行响应(passive)
- Candidate: 新Leader的候选人

任期Term:任期有自增ID,termID最高的Leader有话语权。每个任期从一次选举结束,如果选出Leader,则在Leader挂掉时任期结束;如果没有选出Leader,则开启新的Term
选举过程
- Follower→Candidate
- termID++
- 发起对自己的投票
- 收到大多数赞成→成为Leader
- 收到一个有效Leader的消息→变为Follower
- 没有一个candidate变成Leader→重新发起下一轮选举
如何降低选举失败的可能?
——设置随机数,防止同时变为Candidate并发起投票
日志复制
日志结构:
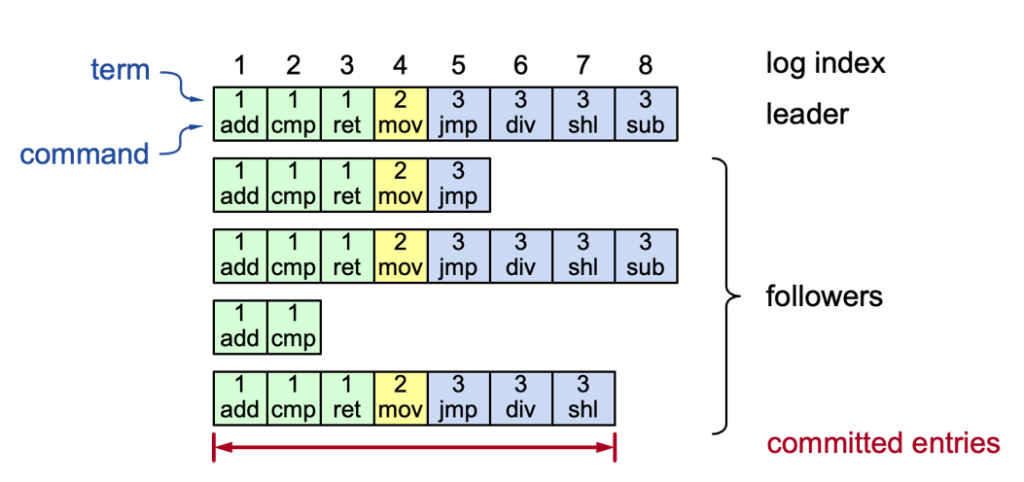
过程:
- 客户向Leader发送指令
- Leader将指令添加到自己的日志中
- Leader向Follower发送AppendEntries RPC
- 如果Leader收到了大多数ACK,则将日志标记为committed
- Leader将命令发给自己的状态机,结果返回给用户
- 将committed entires告知follower,follower将命令发给自己的状态机
解决日志不同步
在AppendEntries时,先校验前面的内容,如果发现不同,则Follower的日志会被覆盖掉,以Leader的日志为准
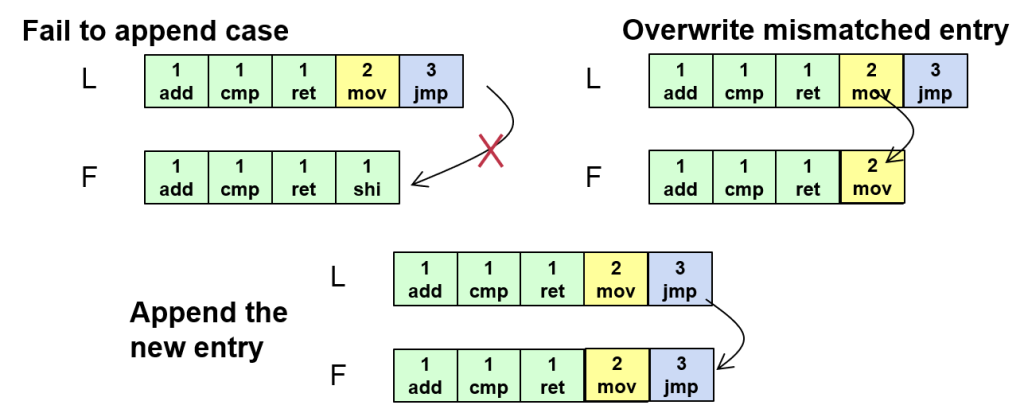
也就导致即便有一条日志被大多数Follower接受,仍然有可能被覆盖掉
那么如何尽可能避免被覆盖掉的情况?
——选举时Follower检测Candidate的日志是否比自己新,如果比自己旧则拒绝投票
但是仍不能完全避免:
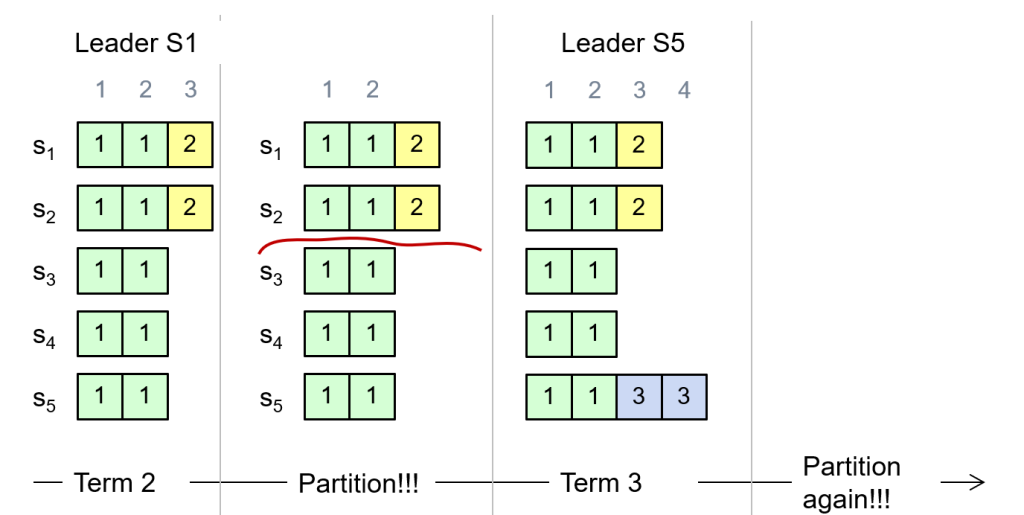
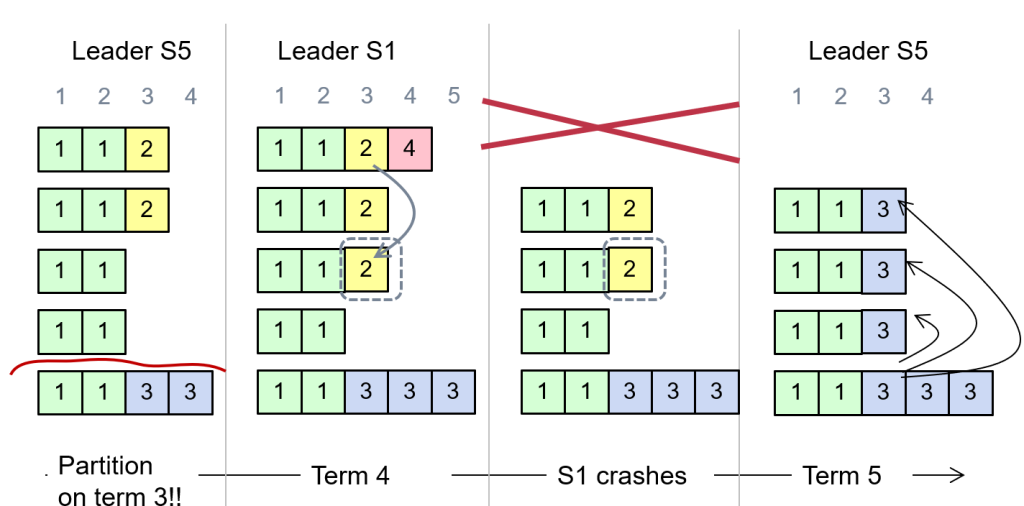
Network
Overview
网络分层:
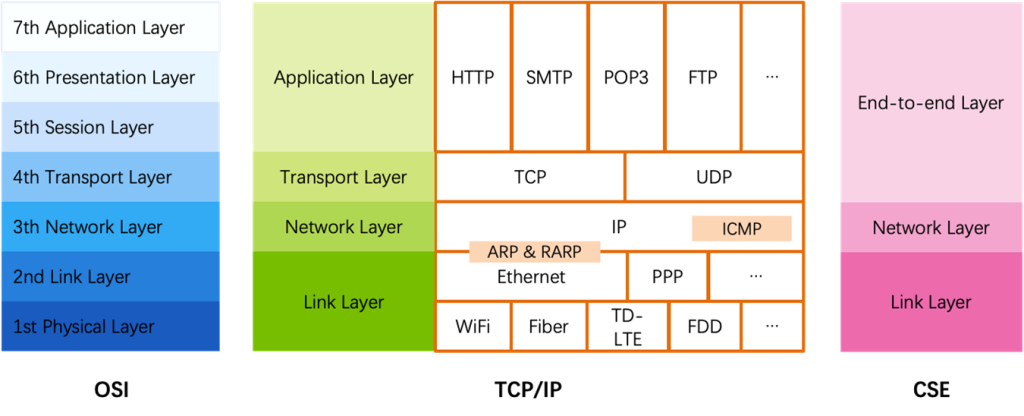
Link Layer
From a node to its physical neighbor
应用:蓝牙、局域网、DJI
同步传输需要精确时钟,仅在CPU等精密部件上使用,网络传输需要异步传输。
初步想法:Three-wire ready/acknowledge protocol
- A将数据存储在data line
- A改变ready line的值
- B看到ready line的值被改变,读取data line的值

为了提升传输速度,只能采取增加并行线缆的方法,但是实际效果不佳,且线与线之间有干扰,所以目前还是使用一根线串行传输。USB-通用串行总线
USB可以借助一个物理元件VCO实现数据无损传输,但问题是如果出现大量连续的1/0,VCO无法识别时钟,也就导致无法识别数据。因此我们需要调整数据传输编码。
曼彻斯特编码:最简单的想法就是0→1+0;1→0+1(根据标准不同,可以相反),避免了电平长时间不变。还有其他不同的编码
单根数据线如何做到并行:按人头分时复用(无法处理更多的用户)/数据包
一般采取数据包的形式
如何识别数据包?
——识别包头和包尾
我们规定包头为7个1,数据内如果存在6个连续的1,则在6个1后面添加一个0
处理数据出错——海明编码
基本想法:错一位会落入非法的值,然后被纠正
原理:海明距离
考虑三位编码,可以构建成下图

如果我们需要识别1位的错误,就可以让数据落在 (111,100,010,001)四个点上,这样即便错误1位也可以落在非法的点上;如果我们需要纠正一位的错误,就需要让数据落在(111,000)这样处于对角线的点上,这样可以纠正1位的错误,识别两位的错误。
海明编码:
–e.g. 1101→1010101

| Not Match | Error |
| None | None |
| P1 | P1 |
| P2 | P2 |
| P4 | P4 |
| P1 & P2 | P3 |
| P1 & P4 | P5 |
| P2 & P4 | P6 |
| P1 & P2 & P4 | P7 |
Error的编号恰好是Not Match编号求和
可以纠1位错,检测2位错,有概率检测出3位错。增加了数据量,但提高了容错。
IP Based-Network Layer
网络可以分成两种:Best-effort network & Guaranteed-delivery network,前者不保证成功传输,后者相反。现实生活中后者用在高层网络中。
网络沟通需要一张路由表,Control-plane用于构建路由表,要求准确性,Data-plane通过路由表快速发包,要求性能。
Control Plane
How to find the fastest path from SJTU to USA?
显然我们不存在一张全局表,用于记录从一个节点到另一个节点的最快路径;所以我们在每个交换机上存储一张路由表,用于计算到另一个节点的最快路径
- HELLO protocol:得到自己的邻居
- advertisement:告诉别人“我”认识谁(link state/distance vector)
- 计算最短路径
Link-state
向所有人广播一个list,包括邻居和到达邻居的cost
A发现自己有3个邻居BDF

A向BDF广播自己的邻居是BDF

BDF继续广播A的信息

最后所有设备都得到了这张图的信息,然后做Dijkstra
Distance-vector
告诉邻居“我”认识谁(包括如何到达这个节点)
A发现自己有3个邻居BDF

A向BDF广播自己的邻居是BDF

BDF将自己认识的顶点发送出去,CE收到信息后同样


所有顶点都收到了其他人的信息

然后使用Bellman-Ford,但是一轮不一定得到了最优,所以还需要把自己的值再发送出去。
link-state与distance-vector对比
| link-state | distance-vector | |
| adv包含什么 | 到邻居的距离 | 到每个可到达节点的距离 |
| 谁收到adv | 所有认识的节点 | 邻居 |
| 故障可靠性 | 高 | 低 |
| 性能瓶颈 | 传播节点过多 | 错误处理 |
| 优点 | 快速收敛 | 发送低开销 |
| 缺点 | 如“洪水”般发送,成本高昂 | 收敛时间与最长路径成正比;Infinity问题 |
INFINITY问题

解决方案:Split Horizon

但是上面两种方法都只适合小规模网络
扩展路由
三种方式:
- Path-vector Routing
- Hierarchy of Routing路由等级
- Topological Addressing拓扑地址
Path-vector Routing
——–Advertisements include the path, to better detect routing loops
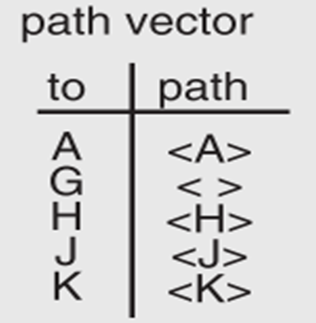
考虑在下图中构建G的路由

G的邻居AHJK发来消息

G形成path vector,并分配端口

G的邻居AHJK再次发来消息

G形成path vector,并分配端口
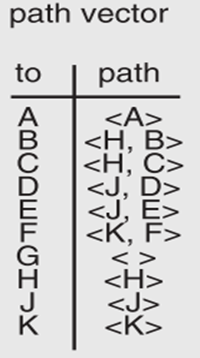
如何避免循环:保证路径不经过自己
如果有多条路径:选取最快的
网络连接断开:忽略包含故障节点的路径,重新advertisement
Hierarchy of Routing
分成不同region,只记录自己region内节点的路径和到其他region的路径
需要IP与地理位置绑定
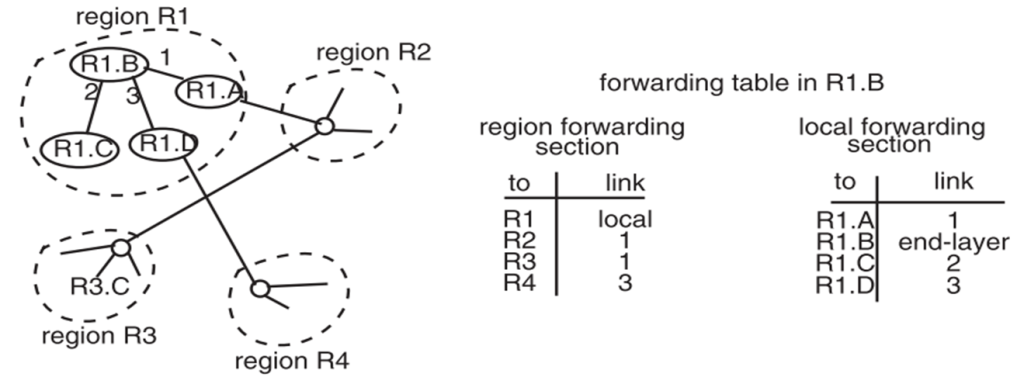
跨region的访问需要通过”BGP”

Topological Addressing
如何简洁地表示连续的IP地址?
——CIDR Notation:(18.0.0.0)→(18.0.0.255)表示成(18.0.0.0)/24,/24代表前24位
Data Plane
交换机如何在几百个Cycle内完成一个数据包的转发?
——甚至不能访问内存
一次需要做的事情
- 查表
- 更新TTL(路由包在网络上转发的次数,超出一定次数则放弃传输),使用专门的硬件进行更新以提高速度
- 发送到对应端口
不要使用sleep,一直轮询
NAT网络地址转换
内网ip无法被外部访问,内网访问外网需要经过Netgate,占用一个对外端口,并以一个统一的ip对外访问
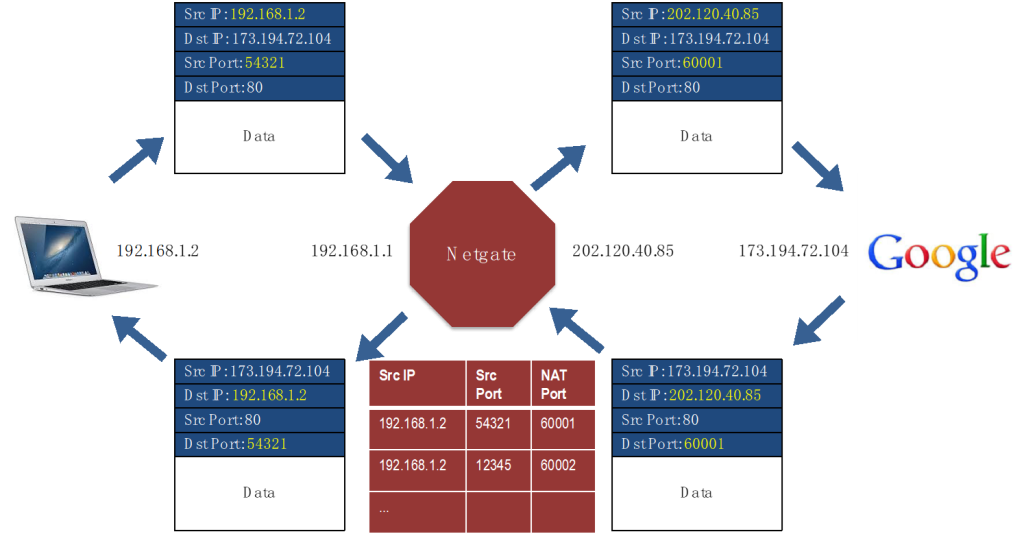
Case Study: Internet到以太网的映射
以太网简介
以太网是一种用于Link Layer的网络,具体介绍如下(微软机翻)
Ethernet is the generic name for a family of local area networks based on broadcast over
a shared wire or fiber link on which all participants can hear one another’s transmissions.
Ethernet uses a listen-before-sending rule (known as “carrier sense”) to control access and
it uses a listen-while-sending rule to minimize wasted transmission time if two stations
happen to start transmitting at the same time, an error known as a collision. This protocol
is named Carrier Sense Multiple Access with Collision Detection, and abbreviated
CSMA/CD.以太网是基于共享有线或光纤链路广播的局域网系列的通用名称,所有参与者都可以在该链路上听到彼此的传输。以太网使用先听后发送规则(称为“载波侦听”)来控制访问,并使用边发送边听规则,如果两个站点碰巧同时开始传输,则最大限度地减少传输时间的浪费,这种错误称为冲突。该协议被命名为 载波监听冲突检测,缩写为 CSMA/CD。
以太网的数据包格式:

以太网的广播方式
Hub与交换机
Hub:如同一条长线,线上的每个人都可以监听消息,所以并不安全
交换机:保存每台机器的Mac地址
以太网的发送-接收

在发送端,ETHERNET_SEND 只将调用传递到链路层。在接收端,检测包的目标是否为自己,如果是自己则进行处理,否则忽略
Layer Mapping
将以太网连接到Network Layer的转发网络
考虑下面的以太网架构(LMN…为ip地址;17/15/18为mac地址)

内网访问:L→N,N会监听到消息,发现数据包的mac地址是自己,然后接收到了消息
外网访问:L→E,由于E不在以太网内,包头中需要包括ip地址“E”和路由器K的mac地址“19”,然后路由器会从4号口将消息发送到其他路由器,为了防止对面的路由器也是以太网,还需要把mac地址从“19”改成E在自身内网中的mac地址
地址解析协议ARP
一个新加入网络的L如何知道其他人的地址?
内网:L知道M的IP地址,希望通过以太网访问,则会发送一个类型为ARP的消息,广播到以太网上的设备上,M收到消息后会回复自己的mac地址
外网:L知道E的IP地址,希望通过以太网访问,路由器会接收到这个消息,告诉L将准备发给E的消息发送给自己,同时在外网上找寻E的位置(或者原本就知道E的位置)
End to End Layer
三种协议
- UDP(User Datagram Protocol):仅仅只是把数据包发出去
- TCP(Transmission Control Protocol):保持顺序,不会丢包,不会有重复包;支持流式控制(控制网络流量)
- RTP(Real-time Transport Protocol):主要用于音视频等流式数据
理想的端到端网络的要求:
- 保证at-least-once
- 保证at-most-once
- 保证数据正确
- 保证数据流的顺序
- 网络波动控制(Jitter control)(不出现大的波动)
- 授权管理及隐私性
- 保证端到端的性能
以上三种协议都无法全部满足7个需求
At-least-once
基本策略:发送包之后,如果一段时间后对方未发送ACK消息,就再发一次
“一段时间”的确定——RTT
RTT(Round Trip time)=之前发包的平均时延+冗余量
实现:
- 发包时包括nonce(id)
- sender保存一份包的数据
- 如果超时则重发nonce对应的包
- 直到receiver返回一个包括nonce的ACK
- 如果retry过多则放弃
确定RTT的三种方法:
- 首先绝不能用固定时间
- 使用Adaptive timer:每遇到一次超时,则将RTT变为1.5倍;当然还有一些改进的方法
- NAK(Negative Acknowledgment):receiver在收到所有包之后告诉sender自己缺失了哪些包,需要receiver维护一个Timer
At-most-once
几种方法:
- 最基本的实现:receiver记下最近的nonce,如果sender重发,则不再处理
——但是无法界定什么时候删除nonce - 请求保证幂等性
- nonce自增,记下见到的最高nonce,忽略nonce低的请求。——如果乱序怎么办
- 每个端口只服务一次请求,如果端口10000收到了一个包,下一次使用10001,但是什么时候能复用端口?
Anyway,没有完美的方法
数据正确
基本想法:checksum校验,但是总有数据和校验同时出错的情况
发送顺序
sender告诉receiver一共有几个包,并且每个包涵盖索引
几种方法:
- 收到3号包后,只收4号包,抛弃更大的包
- 维护一个buffer,但是如果网络出问题,会使buffer占用极大的空间
- buffer满了以后,清空buffer,全部重传
- receiver发送NAK,告知sender缺少哪个包
波动控制
解决方法:视频缓冲区,通过时延确定需要多大的缓冲区
授权管理及隐私性
解决:公钥及私钥,私钥不能泄露
端到端的性能
最基本的实现:发包→ACK→发包→ACK…
改进:sender一直发包,receiver收到后发ACK回来
问题:sender一直发包会占用大量的带宽,所以可以发n个,停一会,再发n个
如何确定n——需要考虑带宽和receiver的处理能力
如果带宽充足,那么我们只需要等receiver处理完n个,返回一组ACK,再继续发包 。(固定窗口)

但是等待ACK的时间仍然是被浪费掉的,需要TCP中的“滑动窗口”来解决

异常处理

为了获得最好的表现:window size的设置:window size ≥ round-trip time × bottleneck(瓶颈) data rate
如:sender速率1MBps,receiver速率500kBps,RTT=70ms,单个包大小5kB
则Sliding window size=500kB*70ms=35kB(一个窗口发7个包)
问题是网络状况会改变,如何解决?
TCP堵塞控制
谁来负责冲突控制
network layer:可以直接感知到堵塞;最终决定如何处理超额数据包
end to end layer:可以通过收到ACK判断,但是并不高效
为了防止拥堵,我们不能无限地发包,还需要给Sliding window size设定一个上界
为了防止拥堵:window size的设置:window size ≤ min(RTT × bottleneck data rate, Receiver buffer),显然性能和防止拥堵是矛盾的。
堵塞控制
- 缓慢增加包的数量
- 如果没有发现丢包,则继续增加
- 如果发现丢包,则快速降低包的数量(保守的方式)
需要考虑的问题:
性能:即便降低包的数量,也不能过于低,需要尽可能占满瓶颈流量
公平性:共享瓶颈的发件人需要获得相等的吞吐量
AIMD(Additive Increase, Multiplicative Decrease)
每个RTT中:
- 网络状况好: cwnd = cwnd + 1
- 部分丢包: cwnd = cwnd / 2
- 全部丢包:从头开始
问题:初始值是1,初始增长过慢,解决方案是第一次增长按指数级,cwnd=2*cwnd,之后都是加法

这里是一个比较保守的做法,尽可能地不对网络产生压力;如果是数据中心等网络状况良好的方法,降低的幅度可以变小。
AIMD可以保证带宽分配公平性,原理如下图

TCP的缺点
- 路由器需要buffer,过大就会影响性能
- 在无线网中,遇到网络信号问题不应该减少发包数量,而应该增大(因为不是网络流量瓶颈)
- 在数据中心中表现不好
- 对于RTT较大的情况有“偏见”
DNS域名系统
我们需要通过“www.smzytyzg.tw.cn”这个域名,得到149.88.86.140:80这个IP地址加端口。如果没有域名,对于程序不会有任何影响,但是对于用户不友好。
一个域名可以具有多个IP地址,方便负载均衡、提高用户承载
一个IP地址可以有多个域名,只需要多个端口
域名与IP地址的绑定可以改变
通过域名找到IP
起初是放在一个txt文件中,但是很不方便
BIND系统
将域名分层。.com;.cn等根域名分别由不同的DNS服务器管辖,如se.sjtu.edu.cn,每个后缀层层下放,每人只管理自己和下一层(类似文件系统)
于是我们可以按下面的过程获得一个域名的ip地址

但是我们认为这样造成的网络请求过多,有两种改良方式
- 使用自己的DNS服务器/在本地存储结果,优先从指定的服务器/本地获取域名到IP的映射
- Recursion:由根节点获取全部域名,再返回给用户。服务器间网络带宽普遍高,能获得更好的性能
- Cache:Recursion对root的要求极高。所以实际上并不是非常的“等级分明”,下层DNS服务器会使用cache,存储一定量的其他“域名-ip”映射,有网络请求时会先访问下层DNS服务器,如果找不到再去root询问。需要设置一个合理的过期时间

DNS的优缺点
优点
- 层级架构去中心化
- 域名全球可用
- 性能可扩展
- 管理可扩展
- 容错
缺点
- 受到当地政策影响www.baidu.com
- 根服务器负载过重
- 安全性 (恶意的DNS服务器)
内容分发网络CDN
docker镜像、b站视频等内容,在分发时可能会造成很大的网络压力,那么除了压缩视频码率,我们能做些什么
——内容分发,将同样的内容在全球各地的服务器上建立多个副本,以达到最佳的访问性能。
用户通过多次DNS搜索,得到最近的服务器,如果服务器内没有该内容,服务器会从中心服务器获取,发给用户的同时,存储到自己的cache内
P2P(Peer to Peer) Network
——No Central Server
BitTorrent比特洪流
特点:
- 分布式资源共享:用户从其他人那里下载文件的片段,而不是从单一的来源。
- 边下载边上传:用户在下载文件的同时,BitTorrent 会将已经下载的部分分享给其他用户。
- 持续分享(种子保持活跃):文件下载完成后,BitTorrent 客户端会继续运行一段时间(成为“种子”),将文件分享给其他用户。
三个角色:
- tracker:记录每个文件的每部分在哪里
- seeder:有整个文件
- peer:有一部分文件
执行过程
- 文件发布者将文件的基础信息(.torrent文件)发布到一个网站上(tracker的url,文件名及大小,hash校验码)
- tracker组织一个peer的群,分别拥有文件的不同部分(有重复)
- Seeder将文件的种子发布出去(指向网站上的.torrent文件)
- 下载者先通过种子获取.torrent文件,再获取到tracker的url
- tracker返回一个peer的列表
- 下载者从peer处进行下载
BitTorrent的缺点:依赖tracker;规模很难扩大(tracker需要跟踪每个用户的加入、离开,来保证数据完整性)
为了解决问题,我们将tracker的数据存储在一个分布式哈希表上
DHT分布式哈希表
- 用于快速查找负责的peer
- 每个节点存储一部分哈希表
- 不严格保证数据的时效性
如何确定需要的key在哪个服务器上:
我们对key做一次哈希,再对服务器的ip地址做一次哈希,得到下表

将哈希值构建成一个环,每个服务器负责那些哈希值落在自己逆时针方向的key。当我们访问key的值,只需要计算一次哈希值,然后不断顺时针旋转,就能找到最终的服务器。
现在我们将O(n)的算法提升到O(log n):每个服务器保存其顺时针方向的多个服务器地址,我们不需要一个一个找寻服务器,可以直接通过当前服务器保存的节点,跳过不属于哈希范围的服务器

如果服务器挂了怎么办:
- 一个key保存在其顺时针方向上的多个服务器,这样可以保证数据不会丢失
- 同时,每个节点保存其后方几个节点(successor list),可以方便跳过损坏节点
如果哈希值分布不均匀:构建出hash值不同的虚拟节点,分配到不同服务器上
Distributed Computing
训练一个大模型所需要的算力是可以算出来的,大致是6 * #parameters * Batch size
如何提升算力:
- 单核设备算力提升:流水线、超标量、超10G
- 单核设备算力再提升:SIMD:一个指令执行多个浮点操作(有物理上界)
- 多核
- 对于某些计算做专门的硬件
roofline model:用于确定性能瓶颈在计算/访存
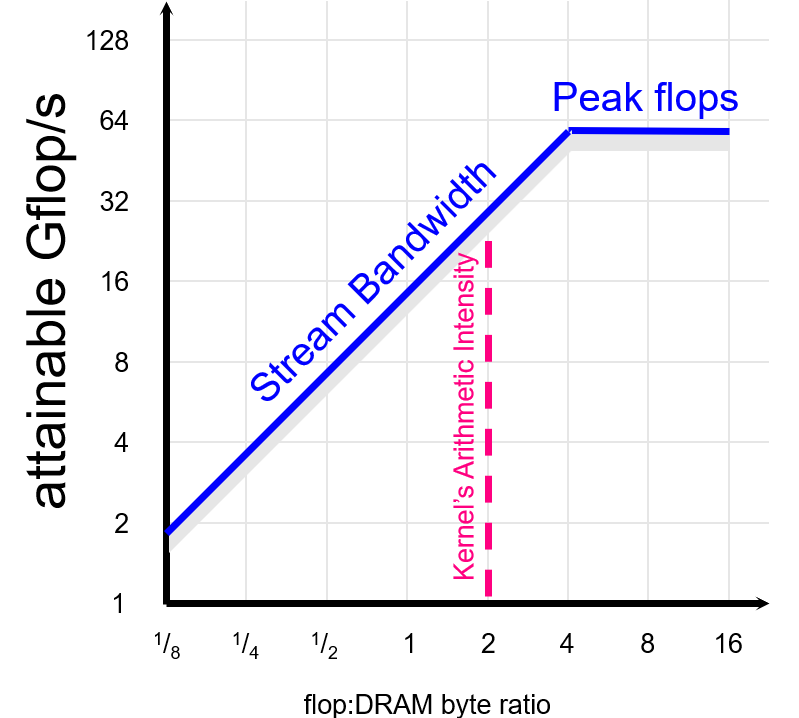
具体而言,x轴是读取一个Byte能做多少次浮点计算,y轴是浮点算力
我们知道,做大规模计算,单机显然是不够的,所以我们需要集群
目前我们有各种各样的框架,可以在集群中做各式各样的任务
- 批处理:Hadoop、Spark
- 图数据处理:GraphLab
- 机器学习:TensorFlow、Pytorch
批处理
MapReduce
基本想法:先分工(map),再合并(reduce)
需要解决的问题
- 节点间的数据传输方式
- 如何协调各个节点的工作
- 错误处理
- 对局部性进行优化(尽量不访问其他节点的数据)
- 将数据分区以开启并行
两个函数
- Map(fuction, set of values):将每个set分别作为function的输入,然后得出一个结果
- Reduce(fuction, set of results):将所有result的结果通过function进行汇总
Map很容易并行,但是Reduce在我们目前的描述中不能并行。在处理一些问题时Reduce也是可以并行的(比如word count)。
执行流示意图
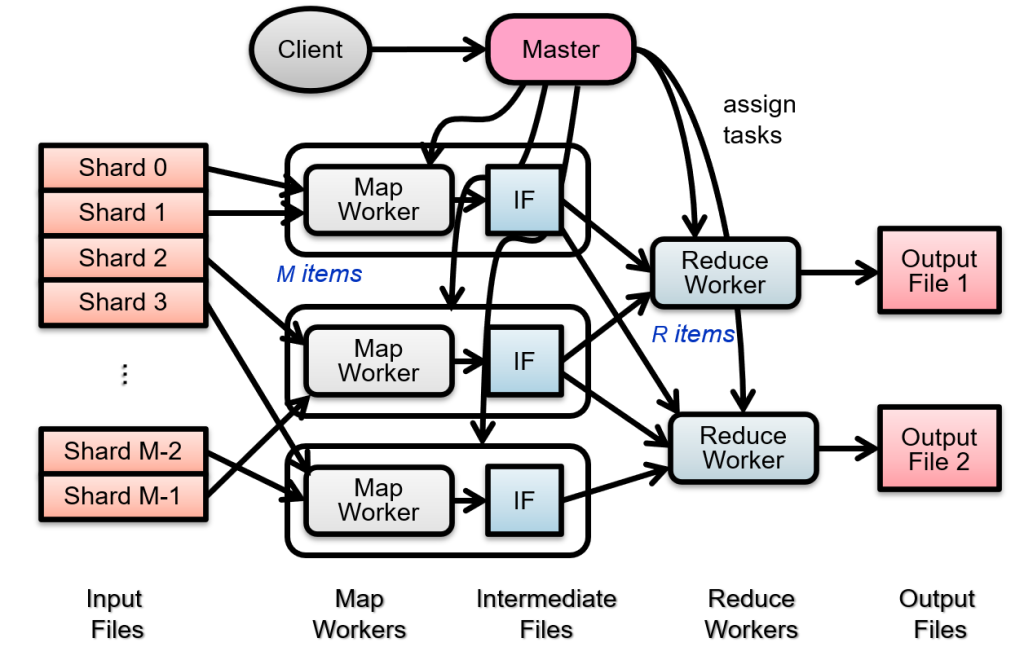
具体实现:
- 如何做sharding:由于运行在GFS系统上,所以一个切片64MB
- 任务调度:master将任务分配给空闲的MapWorker
- 执行Map:读取sharding中的内容,得出结果(键值对),存储在内存中
- 结果存储到Intermediate File中(要分块,以便每个ReduceWorker能够快速找到)
- 对全部的结果进行排序,将上面分的块按ReduceWorker排在一起
- 由ReduceWorker进行合并并输出最终结果
截至目前我们解决了问题中的1、2、5,还有错误处理及局部性优化需要解决
错误处理:
- worker出错:master持续ping,如果挂了就把任务重新分配给别人
- master出错:我们将master的状态使用checkpoint存储到GFS中(或任一个可靠的文件系统),如果出错就恢复
局部性优化:
GFS内部服务器按理说不该暴露给user,但是在这里GFS将chunk server及其中存储的shard暴露给master,然后master将对应shard的计算任务分配给对应的服务器,极大减少了通过网络请求获取数据的概率
其他优化:
冗余计算:防止某些机器由于硬件问题,运行速度极慢。我们把一个任务分配给多个人,几个人搞竞赛,显然也浪费了硬件。
优点:
- 易扩展
- 错误处理
- 对于某些任务具有很好的性能表现
缺点:难以处理复杂任务,编程上难度大
计算图-Computation Graph
所有的计算都可以表示成一张有向无环图

好处:无环图容易做错误处理;DAG可以很方便地找到并行任务
执行原理:当执行完一个任务,其子节点的入度-1,每次执行入度为0的点
机器学习
机器学习的训练过程也可以构建成计算图

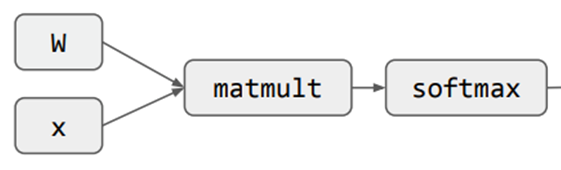
计算图的应用:利用链式法则计算梯度
随机梯度下降
一般的公式:

我们考虑并行,显然只要把求和拆开就行(这种方法叫数据并行,还有一种叫模型并行,我们后面介绍),于是我们可以将计算图做如下的转化,分别计算一部分最后求和

由于机器学习的特点,我们每做完一次上述任务后,需要将结果进行汇总并进行全局广播,而这实际上非常耗时,我们希望能尽量将汇总再广播的AllReduce操作并行执行
AllReduce
需求
- 减少每条信息的数据量
- 减少瞬间流量
Parameter Server
将所有结果发给Parameter server,计算后再广播。显然我们的两个需求都没有被满足

Sharded PS
每台服务器计算1/n的值,降低了PS的负担,但仍有极大的瞬间流量。

De-centralized approach
按距离发送;第一个时间片发送给前一个,第二个时间片发送给前两个。降低了网络流量,但效率较低

Sharding Reduce
我们仍然将一个包拆成n个,对于第0个包,我们采取以下的发送方式,进一步减少的数据量

Ring Allreduce
在上面的方式中,每个节点都要与所有节点通信,有没有办法只与相邻节点连接?

现在每个人有了自己的梯度,还需要做n轮广播,使每个节点都拥有所有的梯度

我们发现梯度计算的顺序并不是严格的w1+w2+w3+w4,在GPU的浮点数实现中,加法不满足交换律(可能是精度丢失?),所以这种方法会导致一定的误差
总结
| Round | Peak node bandwidth 节点同时接收的数据量 | Per-node fan-in 节点同时接收的消息数 | |
| Parameter server (PS) | O(1) | O(N*P) | O(P) |
| sharded PS | O(1) | O(N) | O(P) |
| Decentralized Allreduce | O(P) | O(N) | O(1) |
| Ring allreduce | O(2*P) | O(N/P) | O(1) |
一种更优的方法:Tree Based
我们先构造一棵树,每个节点在树中只出现一次,每个节点将子节点的消息汇总,再发给父节点,但是只有左边一棵树,网络负载不均衡,所以我们将树反转得到右边的树,这样除了0和31两个节点,其他节点都是两进两出,网络负载相对均衡

可以将Ring allreduce的O(2*P)降低到O(log p),其他不变
模型并行
如果你忘了为什么突然冒出来这东西,回去看一下随机梯度下降
数据并行中我们把求和符号拆开,再模型并行中我们把求和式子拆开

具体而言,是因为模型太大了,我们不能做到在每台机器上都保存一个完整的模型以支持数据并行,所以需要对模型进行拆分,形成新的数据流图如下

模型并行还分为两类
- pipeline并行
- tensor并行
pipeline并行
我们按layer分割,将计算任务分配到不同的机器上

就会产生下面这种计算序列

显然上方有很大的空缺(Bubble)没有被利用,我们的解决方法是对Batch进行切割,每计算出一点梯度,就向下传递,达到下图的效果

我们要拆成多少份呢?
我们计算一下Bubble占所需时间的比例=(p-1)/m;p为机器数量,m为batch被分成的份数
为了Bubble所占比例更小:我们需要减少机器数量,很难;增加Batch的大小(这样就可以划分出更多的份数),也很难,受硬件限制。
Tensor并行

机器学习的过程就是计算一个Y=WX的分块矩阵乘法,我们可以对矩阵乘法进行分块,然后再进行汇总,这是Forward pass,还有Backward pass,没看懂

| Pipeline parallelism | Tensor parallelism | |
| 定义 | 按层分割计算图 | 分割层内的参数 |
| 优点 | 减少网络沟通 | 对大模型支持更好 |
| 缺点 | bubbles | 网络沟通较多 |
Information Security
信息安全的三个目标
- 保密性Confidentiality:限制文件读取
- 正确性/完整性Integrity:限制文件写入
- 可用性Availability:保证服务正常运转
Threat Model威胁模型:攻击者会采取什么方式攻击,是一种假设,比如:
- 攻击者位于公司网络/防火墙之外
- 攻击者不知道合法用户的密码
- 攻击者不会弄清楚系统是如何工作的
- ……
显然,上面的威胁模型并不完整,甚至不切实际,但是我们仍需要将一个威胁模型作为我们进行安全系统设计的前提
Password
密码的设计目标
- 能够对用户进行身份验证
- 攻击者必须猜测
- 猜测成本是昂贵的
首先我们考虑偷库的问题
简单想法:在服务器上存储密码的哈希值
显然并不安全,可以用常见密码的哈希进行碰撞
于是我们想到了添加“盐”字符串的方法:我们给每个人分配一个随机的盐字符串,将密码与盐字符串进行哈希,再存储。虽然没有完全规避风险,但是可以使攻击者的进攻成本增加许多倍(因为要对每个人都进行一轮碰撞)
密码保密技术
询问-响应
考虑监听的问题
我们在登录时需要向服务器发送密码,为了防止被监听,简单的想法就是在本地做哈希再上传。
但是哈希仍然可以被监听,我们就需要一种方式,能够使每次的哈希值不同。
我们可以先从服务器请求一个随机数,将密码和随机数一起做哈希,再发给服务器。
这样的问题就是服务器必须保存密码的明文
反向验证
非常不常用,使用类似上面的方式对服务器做校验,防止访问了假的服务器
将离线攻击转化成在线攻击
在注册时,服务器会要求用户上传一张图片,在每次登录时,服务器会要求用户先输入用户名,服务器将图片返回,用户确认图片正确后再输入密码。
那么如果我有一个假网站,我如果想骗到用户的密码,那么我就必须在用户输入用户名后访问真服务器,得到用户的图像,再展示在我的假网站上,以欺骗用输入密码。
这样的后果就是假服务器需要多次请求图片,真服务器可以通过访问次数来发现假服务器,及时止损。
特定密码
为每个软件生成一串密码
N次密码
首先我们需要知道自己登录的次数。在注册时,服务器会对密码+盐做n次哈希
在第一次登录时,我们对密码+盐做n-1次哈希,服务器做一次哈希,再将存储的哈希值替换成n-1次的
在第二次登录时,我们对密码+盐做n-2次哈希,服务器做一次哈希,再将存储的哈希值替换成n-2次的
……
这样的好处是,如果攻击者监听到了哈希值,他必须对哈希做逆向,成本极高
而用户只需要在使用n次后修改密码
时间哈希
实际上就是银行U盾的原理
服务器和用户都保存一个秘密的字符串K,校验时对K+时间做哈希,服务器会检测之前一段时间到现在的时间值是否有同样的哈希
授权与请求绑定
在执行一些操作(付款、转账)等要求用户再输入一次密码
FIDO-Fast IDentity Online
以FaceID登录为例。
我们录入FaceID时,通过物理元件生成了一对保存在本地的私钥和发给服务器的公钥。
在使用FaceID登录时,手机请求服务器,发送一段“挑战码”,用公钥加密;用户需要使用FaceID才能访问储存私钥的元件,并用私钥对服务端的挑战码进行数字签名,然后将签名和对应的公钥ID(用于识别用户)发送回服务端。服务端使用存储的公钥验证签名的真实性。

Security Principles
- Least Privilege最小权限:在完成同样功能的情况下,尽可能减少给予的权限数量
- Least Trust最小信任:因为每个组件都有可能出错,所以我们尽量不去信任其他组件
- Users Make Mistakes:用户可能自己把密码泄露出去
- Cost of Security安全代价:过于提高安全性会导致性能及用户体验变差
ROP-return-oriented programming
什么是“返回导向的”编程
——recall:ICS1-AttackLab,我们通过栈溢出修改%rax的值,使得代码跳转到了我们编写的程序中。这种攻击被DEP(Data Execution Prevention)防御住,因为他标记了内存中的哪些代码是可执行的。于是我们通过“断章取义”,将原有的代码借助多次return拼接出我们想要执行的代码,然后进行攻击。
防御方式:
- 隐藏二进制文件,攻击者就无法获取到汇编代码
- ASLR地址随机化,每次执行都在不同的内存地址执行
- Canary金丝雀,放在return address前,如果Canary被覆盖掉,说明return address不安全
CFI-Control-Flow Integrity
什么是“控制流正确性”
——ROP攻击破坏了代码执行的顺序,我们可以提前构建出执行流图来抵御ROP攻击

构造控制流图
我们首先找到程序里需要跳转的地方,构造出如下的图

添加一段硬编码的随机数data到lib,在跳转前检查跳转地址,如下图。上、下分别为修改前和修改后的汇编代码

问题:假设A可以调用C,B可以调用C、D;因为B对%ecx检查只能有一个值,所以C、D的ID是一个值,也就导致A可以调用D
解决方法:将代码复制,不要让B在同一个地方既能调用C也能调用D;多个ID
问题:A调用F,B也调用F,那么F的return会出现和上面一样的问题
解决:shadow stack,为返回值维护另一个栈
实际上CFI不能彻底防御针对于控制流图的攻击,但已经得到了很好的效果

Blind ROP
假设只知道服务器有栈溢出问题,不知道二进制文件,不知道内存地址空间
发送一个HTTP请求,得到的返回值三种情况:正常返回(无论是网页or404,反正是没崩)/连接断开/kale
假设我们通过栈溢出,覆盖到一部分return address时,我们可以通过n次尝试,得到return address的前几位(错的都崩了,没崩意味着是正确的),同样的攻击方法可以攻破金丝雀
为什么每次地址都一样——因为nginx的服务进程是从父进程fork出来的


如果我们需要进行攻击,就要得到二进制文件;仍然做尝试,我们通过仅修改return address的后两位(一般不会报错),同样可以得到三种情况(正常返回/连接断开/kale)
找到return:
- 我们覆盖两个地址,那么return后就会跳到第二个地址
- 假设我们先将第二个地址设置成断开连接的地址,运行,发现连接断开
- 再将第二个地址改成kale的地址,运行,发现kale,说明第一个地址执行了return
然后我们需要找到能够修改内存的代码,具体而言就是需要找到pop %rdi; return; 之类的代码,显然是很难的,我们从简单的开始。
我们现在需要调用write函数,那么我们需要修改rdi/rsi/rdx三个寄存器的值,外加调用+return

而x86汇编在函数末尾常有以下的代码段,因为这些寄存器是callee save寄存器,所以函数前会有大段push,函数后会有大段pop

我们可以通过连续修改8个return address,然后修改最后一个,看能否引发结果的变化,来判断是不是执行了以上6个pop
而上面这段代码可以通过断章取义执行pop rdi和pop rsi

我们再尝试修改rdx;因为rdx是caller save寄存器,就可以通过调用其他函数修改rdx,而这样的能修改rdx的函数包括系统函数strcmp,而这种函数会存储在PLT中
PLT表有两个特点:地址8对齐;其中全部是可执行的地址,不会导致崩溃
当我们找到PLT表,就可以通过修改rdi、rsi来找到strcmp,方法是通过下面这种方式测试结果

最后我们需要找到write,同样使用PLT表,检查是否能收到一些乱码。
数据流跟踪
我们最初的目标是保护数据,那么能不能通过跟踪数据流动,限制隐私数据发送?
原理:通过计算,禁止jmp到一个被染色(taint为true)(用户可控制)的地址,是动态控制的

原理就是在内存级别做一个taint表,禁止将taint为true的值发送出去。但是taint也是能通过控制流被洗掉的。
Secure Channel安全通道
如何保证设备与设备间的安全
- 两边共享一个密钥key(除非遍历key否则得不到内容)
- mac:key和message一起加密得到token,token用于校验,防止被篡改(中间者可以拦截A到B的消息,并不断给B重发,可以反复让B执行同样的操作,比如解锁车门)
- 在消息中加入一个变化的seq,用于防止反复测试(避免了重发,但是两边的seq是一样的,中间者可以截取A给B的seq,拼接到自己的假消息上,冒充B给A发)
- Diffie-Hellman:两边交换公钥,然后分别用对方的公钥加密,用自己的私钥解密(中间者可以在密钥交换时拦截,然后一直在中间转发消息)
- RSA公私钥加密:A从网络上的权威机构得到B的公钥(或者B给A发送公钥和权威机构发放的证书),具体原理参照SE3308,或者问你的CS室友
Data Privacy数据隐私
OT-Oblivious Transfer
A有两个数据;B想要一个,但是B不想让A知道“我”想要哪个
A生成两对公私钥,分别对应一个数据;B生成一个随机数r,并通过想要的数据的公钥加密,发给A;A得到消息后用两个私钥解密得到k0,k1(其中有一个是r),然后将两个数据分别与k0,k1,做异或,全部发给B;B再和r做一次异或,就能得到自己要的数据
DP-Differencial Privacy差分隐私
B数据库中有各种数据,只支持多条数据一起返回;但是A想得到一个人的数据。显然A可以通过多次反复筛选得到想要是数据。所以B的处理方式是:返回值分段(返回一个近似值而非精确值,有损的);设定询问预算(在数据库未更新前,B只能询问几次)
Secret Sharing
假设n个人共享一个数据,分成n份,而只要有任意k个人就能恢复出数据
原理:S为加密数据,f(x) = S + a1x + a2x + … + ak-1xk-1,n个人拿不同的x,k个人就能解出全部ai
优点:是一个信息理论上安全的协议
缺点:理想假设(至少 k 个部分永远不会串通) 通信开销
HE–Homomorphic Encryption同态加密
能否实现密文加减乘除得到的结果,也是原文加减乘除得到的结果对应的密文(用于云上运算)
SWHE(SomeWhat Homomorphic Encryption)部分同态加密:支持部分操作的同态加密
FHE(Full Homomorphic Encryption)全同态加密:所有运算都支持;做不到
TEE-Trusted Execution Environment可信执行环境
原理:内存加密,加载到cache中变成明文

TEE 可以访问所有 DRAM 和外围设备;REE 无法访问 TEE 的资源
缺点:必须信任硬件厂商