图算法
图的分解
无向图
DFS
DFS(G)
for all v ∈ V do
| visited(v) = false;
end
for all v ∈ V do
| if not visited(v) then Explore(G, v);
end
EXPLORE(G, v)
input : G = (V,E) is a graph; v ∈ V
output: visited(u) to true for all nodes u reachable from v visited(v) = true
PREVISIT(v);
for each edge (v,u) ∈ E do
| if not visited(u) then EXPLORE(G, u);
end
POSTVISIT(v);图的连通性
树边(tree edge):DFS时经过的边
回边(back edge):树边以外的边
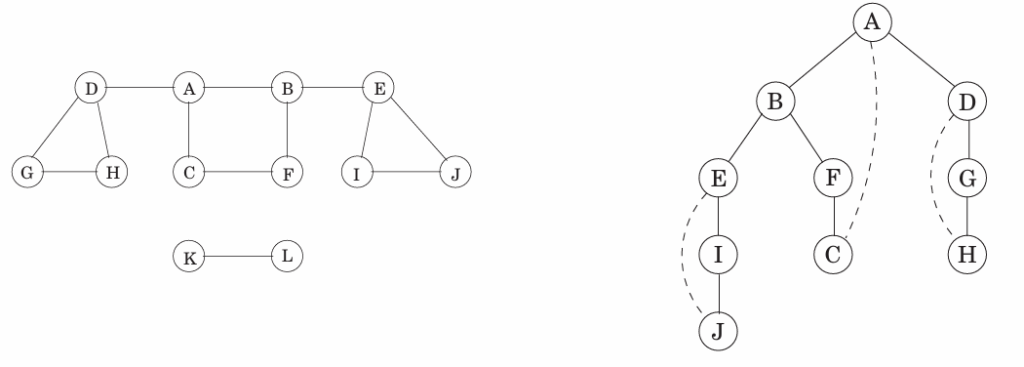
连通图:任意顶点间两两有路径的图
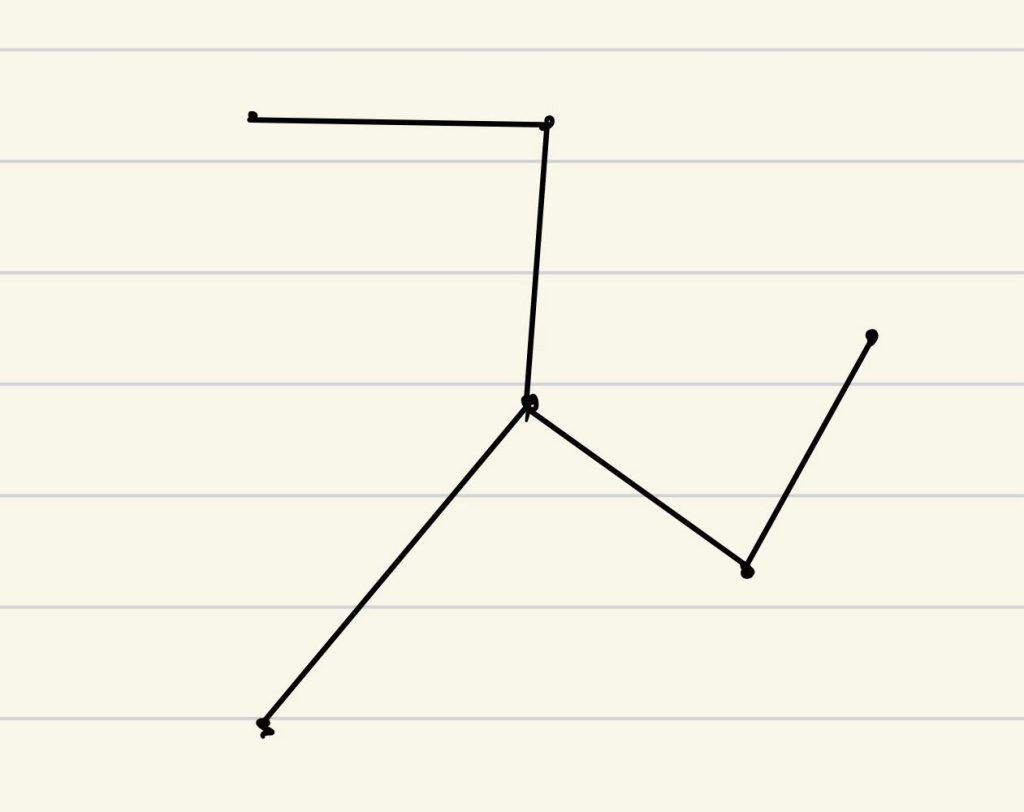
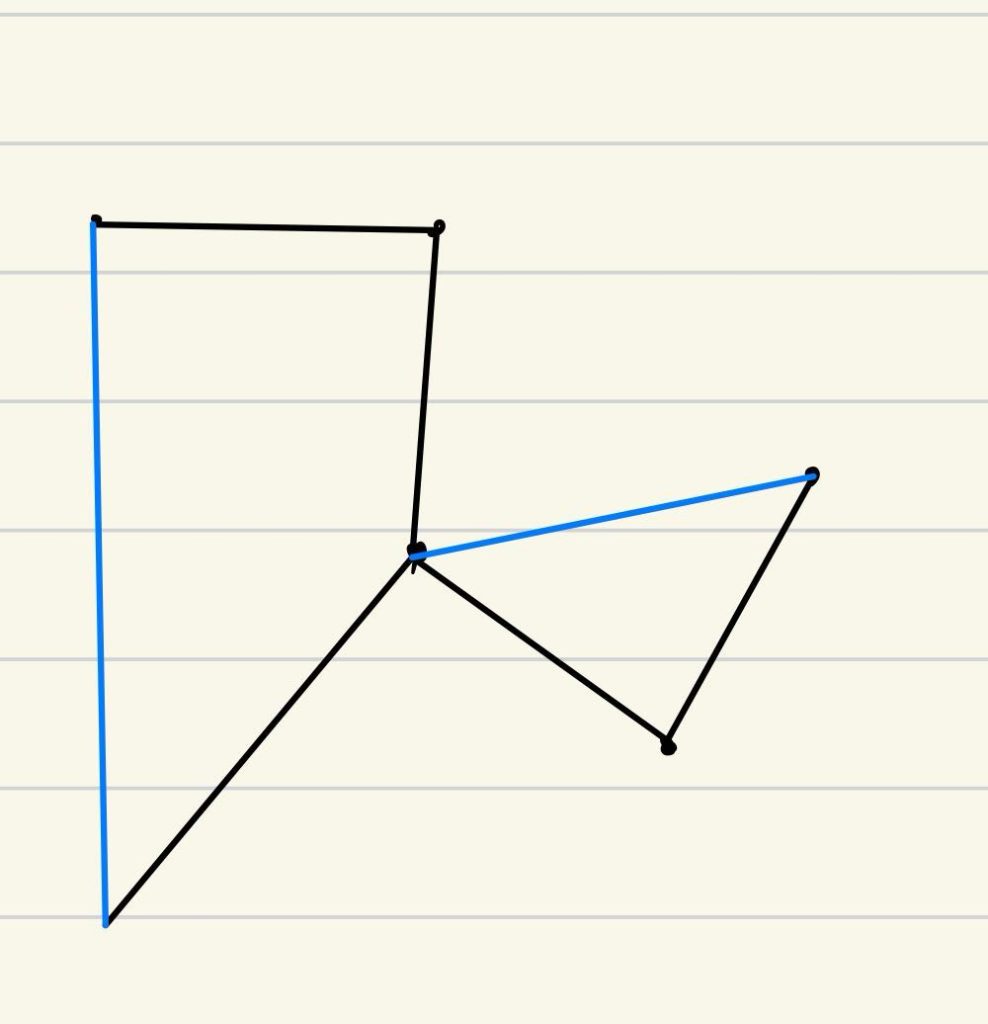
连通部件 /连通分量(connected component):原图的子图,且内部顶点两两间有路径。上图中{A,…,J}、{K,L}都是。
从某个顶点开始的DFS会找出顶点对应的连通部件;每调用一次Explore都会产生一个新的连通部件。
前序及后序
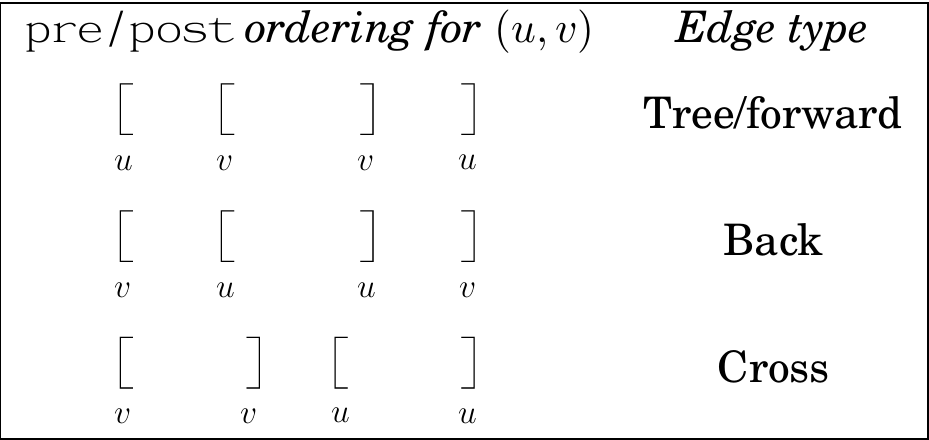
用pre[v]、post[v]表示顶点v第一次和最后一次被访问的时间,DFS结束后,会发现:
[pre[u], post[u]]、[pre[v],post[v]]或不相交,或一个包含另一个
证明:
- 访问u时,uv之间存在一条未被访问的路径(路径上的节点都未被访问),则[pre[u], post[u]]、[pre[v],post[v]]一个包含另一个
- 访问u时,uv之间不存在路径(不连通(如BC)或路径上有点被访问(如BE)),则[pre[u], post[u]]、[pre[v],post[v]]不相交
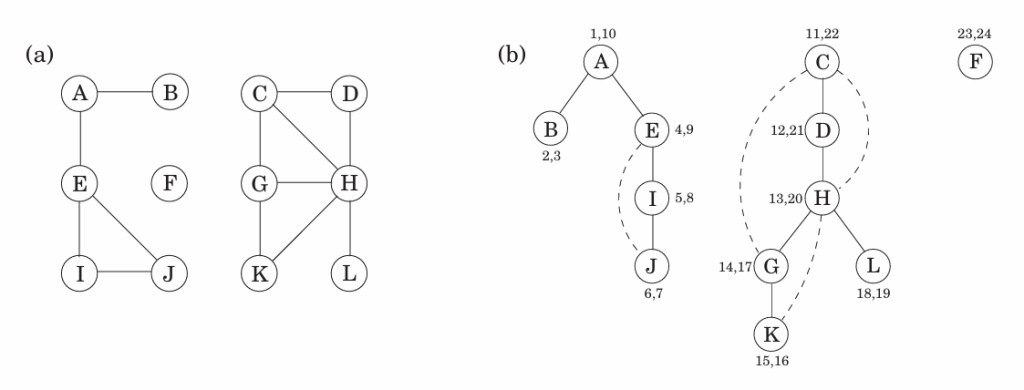
有向图
DFS
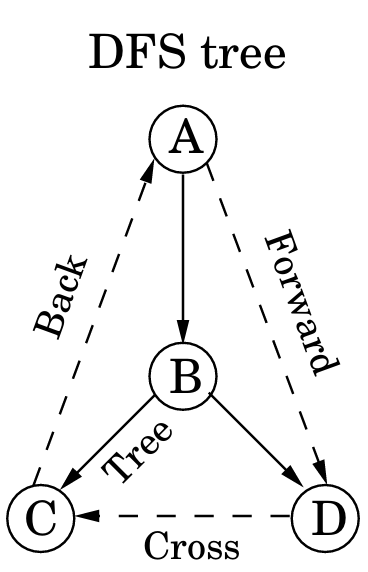
DFS会生成搜索树/森林,产生树根、祖先后代、父子等概念
树边:DFS经过的边
前向边(forward edge):指向非子节点的后代
回边:指向祖先
横跨边(cross edge):去除掉前向边和回边后,从一个顶点指向另一个被完全访问过的边
类比pre[v],post[v],可以用以下方法区分四种边
为什么不存在uuvv这种情况?
证明:存在u→v这条边,若先访问u,分类讨论u到v是否还有其他路径,结果均为uvvu;先访问v,若有其他路径,结果为vuuv,无其他路径则为vvuu
有向无环图DAG
Lemma: 有向图有环,当且仅当DFS有回边
证明:
- 若有环则有回边:假设在环上先访问顶点vk,则vk-1→vk是一条回边
- 若有回边则有环:假设回边为u→v,出现回边意味着存在另一条路径从v到u,则成环
线性/拓扑排序:任意调用一次EXPLORE算法,把所有顶点按post number从大到小排序(后访问靠前)
在DAG中所有边都是排名靠前的节点指向排名靠后的节点
证明:DAG没有回边,而其他三种边都满足这个性质
所有有向无环图均有拓扑排序
DAG⇔DFS无回边⇔有拓扑排序
Lemma: DAG中,e(u,v),post[v]<post[u]
源点(source):没有入边的点
汇点(sink):没有出边的点
Lemma: 每个DAG都有至少一个源点,至少一个汇点
拓扑排序的另一种算法:找到源点,输出,然后从图中删去,再继续找源点
强连通部件/分量
连通:uv之间存在u→v的路径,也存在v→u的路径,则uv连通
强连通分量(SCC):原图的子图,且内部顶点两两间连通。(需要最大化,能合并的必须合并)
源点强连通分量(source SCC):在“超图”(即b图)中,源点对应的强连通分量({A})
汇点强连通分量(sink SCC):在“超图”(即b图)中,汇点对应的强连通分量({D}和{G,H,I,J,K,L})
可以将图分为多个互不相交的SCC
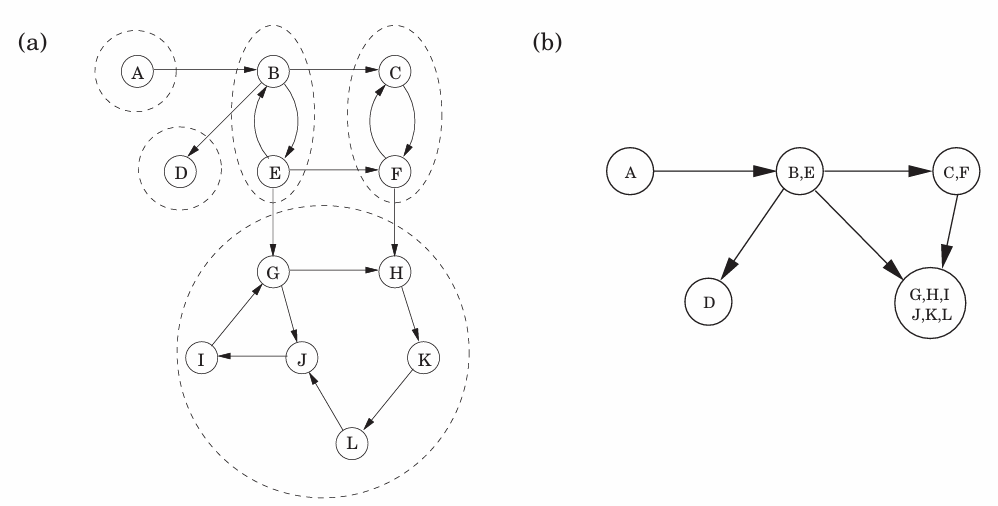
Lemma: 每个有向图关于其SCC是一个DAG,上图中左侧有环,右侧无环
求出强连通部件
Lemma1: DFS时,一次Explore从u点开始,那么该进程恰好会在 所有u可达的顶点v被访问后 停止
所以,如果顶点u在一个汇点强连通分量中,我们恰好能得到这个强连通分量。
问题:
- 如何找到处于汇点强连通分量中的顶点u
- 找到一个强连通分量之后怎么办
解决第一个问题:
Lemma2: C,C’是两个SCC,存在一条边C→C’,则C中最大的post[u]大于C’中最大的post[u]
Proof:拓扑排序
根据Lemma2可以得到下面的Lemma3
Lemma3: post[u]最大的u必定落在一个源点强连通分量中
考虑原图的反转图(reverse graph),即G中e(u,v)→G’中e(v,u),G’中的源点强连通分量恰好是G中汇点强连通分量,因此在G’中做DFS可以解决第一个问题。
解决第二个问题:
根据Lemma3,删除第一个SCC后,剩余的post[v]最大的顶点恰好落在G中下一个汇点强连通分量中,因此可以一直应用这条性质直到结束。
线性时间的算法:
- 在G’上做DFS
- 按上一步中post[v]降序的顺序,在G上运行DFS(访问过的不再Explore)
相关问题:
团问题
把图分成n个两两之间有边的部分(无多项式时间算法)
关键路径
ps:假设所有路径长度都为1
- 进行遍历,标记每个顶点的入度
- 完成入度为0的任务
- 更新一遍入度,重复步骤2-3直到结束
给定有向图,找到一顶点可以到达所有其他顶点
法1:
- 绘制“超图”
- 如果有多个源点强连通分量,则不存在;如果只有一个源点强连通分量,则这个SCC中的任意一个点都满足
法2:
- 调用DFS,找到post[u]最大的顶点u
- 从u开始DFS,如果访问了所有顶点,则满足条件
最小生成树
问题描述:给定G(V,E),在其子图H(V,T)中,使H不破坏图的连通性且T的权重和最小。
路径:连接了一个顶点序列的边的序列
环:一条首尾相接,没有重复顶点的路径
割:定义在顶点集V上的一种分割,将V分割为S和V-S两个非空集合
割集:横跨V和V-S两个顶点集的边的集合
性质:一个环和一个割集的交集必定有偶数条边

基本环:令H(V,T)为图G(V,E)的一颗生成树,e∉T,则T∪{e}会形成一个环C,称为一个基本环
对任意f∈C,T∪{e}-{f}仍是一颗生成树
基本割集:令H(V,T)为图G(V,E)的一颗生成树,f∈T,T-{f}将G分为两部分,令D为横跨两部分的边的集合,称为一个基本割集
对任意e∈D,T∪{e}-{f}仍是一颗生成树
红蓝染色算法
- 红色规则:在没有红边的环C上找出最长的边染红
- 蓝色规则:在没有蓝边的割集D上找出最短的边染蓝
- 不断应用上述两条规则(顺序不定),直到所有边都被染色,则蓝边为MST(可以在染色|V|-1条蓝边后终止)
证明正确性
假设:存在一个可能的最小生成树MST(V,T*)包括当前所有蓝边,不包含任何红边
base:未运行时一定成立
归纳:运行到某一步(假设这一步染蓝色)时:
1.如果染色边f∈T*,显然满足;
2.如果染色边f∉T*,则T*∪{f}会形成一个基本环,环和割集的另一个公共边是e(显然e不比f短),则MST(V,T*-{e}+{f})是一棵满足假设的最小生成树
归纳:运行到某一步(假设这一步染红色)时:
1.如果染色边f∉T*,显然满足;
2.如果染色边f∈T*,则T*-{f}会形成一个基本割,环和割集的另一个公共边是e(显然e不比f长),则MST(V,T*+{e}-{f})是一棵满足假设的最小生成树
证明算法终止
只需证明一条边或被染红,或被染蓝
选取一条未被染色的边e,算法运行时蓝边形成一个森林,会出现以下情况
1.e的两个端点在一棵树中,则e与这棵树形成了一个环,可以应用红色规则
2.e的两个端点在两个树中,则e属于一个割集,可以应用蓝色规则
Prim算法
假设AB两部分分别有两颗最小生成树S,T,选取A→B最短边e,S∪T∪e是整体的最小生成树
- 选取一个顶点添加到T中
- 选取一条T到V-T的最短边e(u,v),将v添加到T中(假设u原本在T中)
- 重复上一步|V|-1次
algo:
PRIM(G, w)
input : A connected undirected graph G = (V, E), with edge weights we
output: A minimum spanning tree defined by the array prev
for all u ∈ V do
| cost(u) = ∞;
| prev(u) = nil;
end
pick any initial node u0;
cost(u0) = 0;
H =makequeue(V) using cost-values as keys;
while H is not empty do
| v=deletemin(H);
| for each (v, z) ∈ E do
| | if cost(z) > w(v, z) then
| | | cost(v) = w(v, z); prev(z) = v;
| | | decreasekey (H,z);
| | end
| end
end
证明:相当于只画蓝色边
时间复杂度O(|E|·log|V|)
Kruskal算法
- 将所有边按权值升序排列
- 按顺序遍历所有边,添加到图中,如果成环舍去
algo:
KRUSKAL(G, w)
input : A connected undirected graph G = (V, E), with edge weight we
output: A minimum spanning tree defined by the edges X
for all u ∈ V do
| makeset (u);
end
X = { };
Sort the edges E by weight;
for all (u, v) E in increasing order of weight do
| if find (u)≠find (v) then
| | add (u, v) to X;
| | union (u,v)
| end
end使用的数据结构:不相交集/并查集
- makeset(x): create a singleton set containing x; |V|
- find(x): find the set that x belong to; 2·|E|
- union(x, y): merge the sets containing x and y; |V| – 1
证明:是红蓝染色算法的特殊情况
选中一条边e,若e的两个端点在一颗蓝色树中,则应用红色规则将e染红;否则应用蓝色规则将e染蓝
时间复杂度:O(|E|·log|E|)(排序的复杂度),纯算法复杂度为O(|E|)
Reverse-Delete算法
将E中边按权重从大到小排序,如果删除边e不影响连通性,则删除,否则保留(相当于持续应用红色规则)
时间复杂度:O(|E|log|V|(loglog|V|)³)
Borůvka’s算法
把图中当前的连通块看成“组件”(初始时每个点就是一个组件)。在每一轮里:
- 对每个组件,找一条从该组件出发、连接到其他组件的最便宜的边。
- 把所有组件各自选出的这些最便宜边一起染成蓝色。
- 重复上述步骤,直到只剩下 1 个组件(或选边数达到 (n-1))。
时间复杂度:O(|E|log|V|),每轮选边是|E|,组件数每轮减半,最多log|V|轮
如何实现组件的合并——压缩边
压缩边
目标:删除组件内部的边,组件之间的平行边保留权重最小的
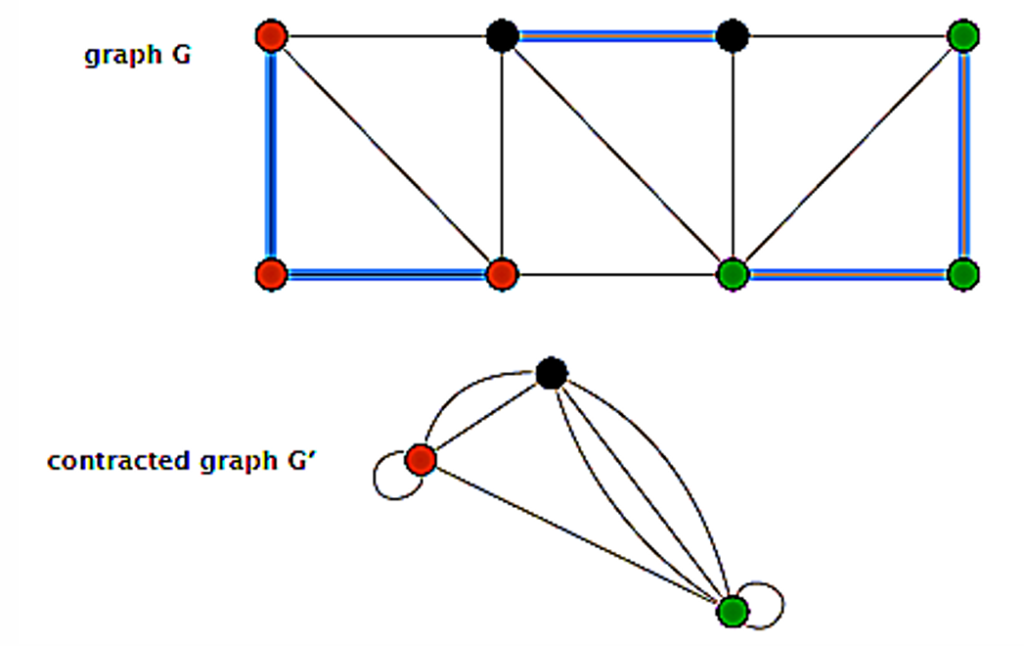
- 标记需要被压缩的边O(|V|+|E|)
- 识别压缩后生成的新组件O(|V|+|E|)
- 将每个组件替换为一个顶点O(|V|+|E|)
- 删除自循环边和平行边O(|E|)
时间复杂度:O(|V|+|E|)
动态规划
有向无环图DAG的最短路径
注意到:在DAG的任意路径中,顶点按拓扑序出现
DAG-SHORTEST-PATHS(G, l, s)
input : Graph G = (V, E), edge length le e ∈ E ; Vertex s ∈ V
output: For all vertices u reachable from s, dist(u) is the set to the distance from s to u
for all u ∈ V do
| dist(u) = ∞;
end
dist[s] = 0;
linearize G;
for each v ∈ V\{s} , in linearized order do
| dist(v) = min(u,v)∈E {dist(u) + l(u,v)};
end允许负边存在
求最长路径:将所有边长取负
for循环在解决子问题{dist(u): u∈V},最初的子问题是dist(s)=0,然后逐渐解决一个更大的子问题
最长递增子序列
问题描述:给出序列a1,…,an,给出一个有序的子序列ai1,ai2,…,aik,其中1≤i1<i2<…<ik≤n,使k最大。如:

算法:
- 按大小关系构建DAG
- 找最长路径
- 第一种方式:将所有边长取负
- 另一种方法:
for j=1 to n do实际就是第一种方法把min改成max
| L(j)=1+max{L(i)|(i,j)∈E};
end
return maxjL(j);
两种算法的时间复杂度都是O(n2),因为构建DAG就是O(n2),循环最差也是O(n2)
事实上L(j)=1+max{L(i)|(i,j)∈E};可以用一个递归程序解决,但是使用递归会导致复杂度变成指数
序列对齐 编辑距离
编辑距离:将两个字符串通过添加空格和修改的方法对齐,最少需要几个空格和修改
可以对“空格”和“修改”给予不同的权重,甚至不同字母对间的修改权重也可以不同
序列对齐:希望在编辑距离的基础上,给出最短编辑距离的情况下,对齐的部分

对于原问题构建子问题
- 假设字符串x,y的长度为m,n,E(i,j)表示x[1…i],y[1…j]时的编辑距离
- E(i,j)的取值无非三种
- 仅x变长,y增加一个空格:1+E(i-1,j)
- 仅y变长,x增加一个空格:1+E(i,j-1)
- xy同时变长:diff(i,j)+E(i-1,j-1)
例:求EXPONENTIAL和POLYNOMIAL的编辑距离时,解子问题E(4,3),前缀EXPO和POL,对应三种取值
事实上,编辑距离的计算可以看成填写下面这样的表格
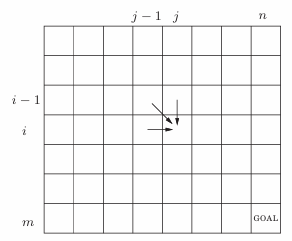
algo:
for i = 0 to m do
| E(i,0) = i;
end
for j = 1 to n do
| E(0,j) = j;
end
for i = 1 to m do
| for j = 1 to n do
| | E(i,j) = min{1+E(i-1,j),1+E(i,j-1),diff(i,j)+E(i-1,j-1)};
| end
end
return(E(m,n));
diff(i,j)
return x[i]==y[j]解决编辑距离后,再解决序列对齐:需要找出答案得出的路径,可以得出答案后逆向寻找一次(traceback),额外空间及时间O(m+n);或者在填表时用额外空间记录O(m·n)
填了一个m·n的表,时间复杂度O(m·n)空间也是O(m·n)
空间可优化:因为填表是一行一行填,我们只需要保存上一行就行,此时空间复杂度为O(m+n),因为需要traceback
将动归表构造成如下的DAG,编辑距离是右下角到左上角的最短路径
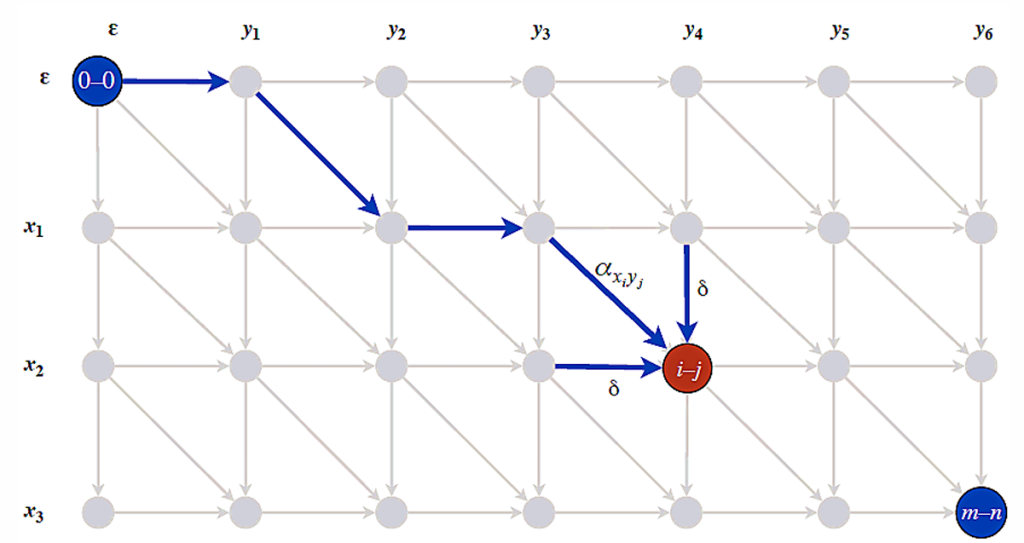
目前时间复杂度仍为O(m·n),可以采用分治法(从0到n/2,从n/2到n),分成两段最短路径分别计算
注意仍然是计算n/2整列,因为不能确定最短路径经过列上哪个点
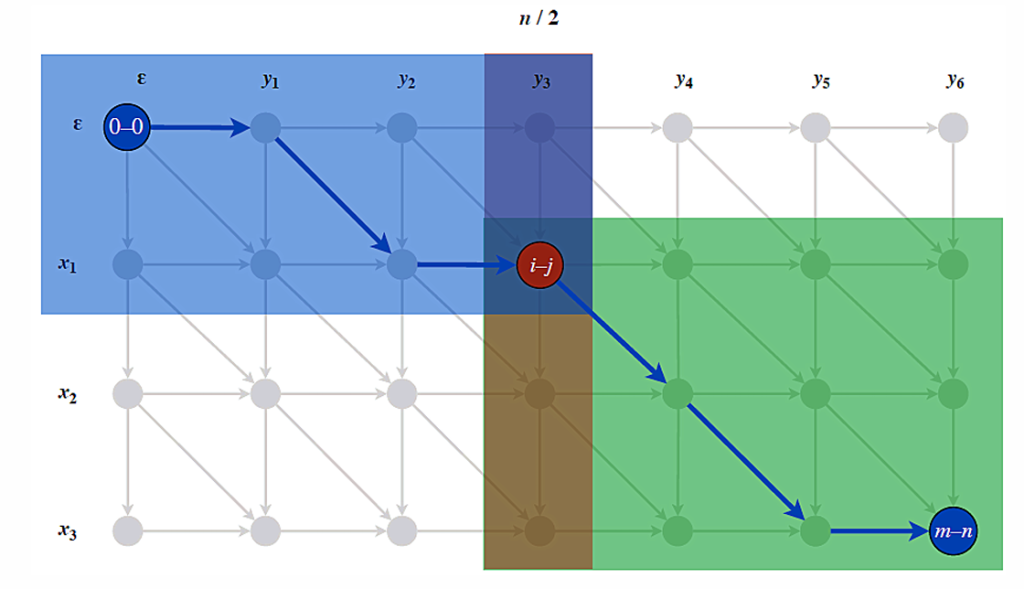
此时空间复杂度为O(min{m,n}),时间为O(m·n)
最长公共子序列LCS
问题描述:给定x[1,…,m],y[1,…,n],分别删除x,y的一部分,使得剩下的字符串相同,这个字符串最长是什么
例:LCS(GGCACCACG, ACGGCGGATACG ) = GGCAACG
![LCS[i,j]=\left\{\begin{array}{lr}& 0\\& LCS[i-1,j-1]+1\\&max\{LCS[i-1,j],LCS[i,j-1]\}\\\end{array}\right.\begin{array}{lr}& if\quad i=0 \vee j=0\\& if\quad a[i]==b[j]\\& otherwise\\\end{array}](https://www.smzytyzg.tw.cn/wp-content/ql-cache/quicklatex.com-d7f10b2db3bab1f65b7a5b713e5cf0d3_l3.png "Rendered by QuickLaTeX.com")
相关问题:最长公共子串
![LCS[i,j]=\left\{\begin{array}{lr}& 0\\& LCS[i-1,j-1]+1\\&0\\\end{array}\right.\begin{array}{lr}& if\quad i=0 \vee j=0\\& if\quad a[i]==b[j]\\& otherwise\\\end{array}](https://www.smzytyzg.tw.cn/wp-content/ql-cache/quicklatex.com-af357cc187ce9f411d4118743164ed7e_l3.png "Rendered by QuickLaTeX.com")
有负边无负环的最短路径——贝尔曼·福特算法
ShortestPaths(V,E,l,t)
for each node (v ∈ V) do
| dist[v, 0] ← ∞;
end
dist[t, 0] ← 0;
for i = 1 to n−1 do
| for each node v ∈ V do
| | dist[v, i] ← dist[v,i − 1];
| | for each edge (v,w) ∈ E do
| | | dist[v, i] ← min{dist[v,i],dist[w,i − 1] +lvw};
| | end
| end
end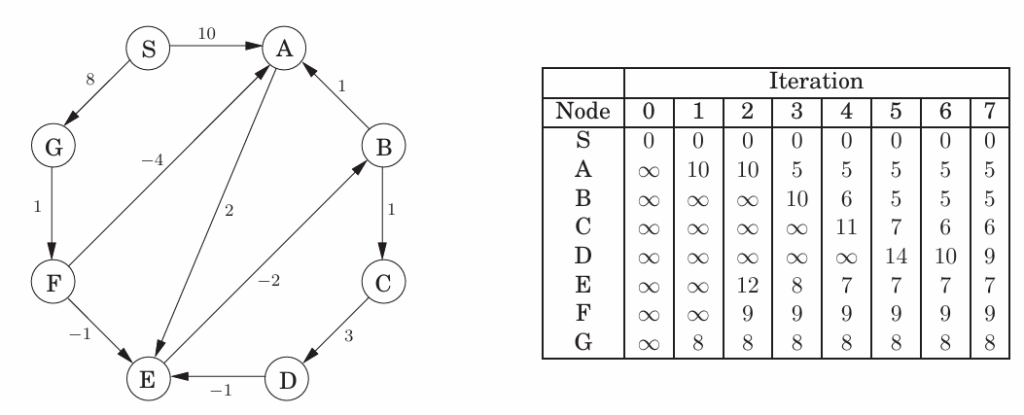
问题:负环的出现使得路径无意义
解决:在|V|-1轮以后再进行一轮,如果有值变化则存在负环
时间复杂度:O(|V||E|)
空间复杂度:O(|V|²)
优化:只需要一列,直接在这一列上更新即可,再用额外的数据结构记录最短路径。空间降为O(|V|)
最短可靠路径
问题描述:求两点间最短路径,但限制最多经过k个节点
F(i,v) 表示经过i个节点到达v节点的的最短路径
递推式:F(i,v)=min{mine(u,v)∈E{F(i-1,u)+l(u,v)},F(i-1,v)}
内层min表示表示求恰好经过i个节点的最短路径,外层min表示可以经过比i小个节点
使用瞪眼法,可以发现恰好是贝尔曼·福特算法填表的前k列
多源最短路径All-pairs shortest path
问题描述:得出图中任意两个顶点间的最短路径
显然,我们可以在每个节点上做一次贝尔曼福特算法,复杂度O(|V|2|E|),因为点一般比边少,所以目标是O(|V|3)
Floyd-Warshall算法
将顶点编号1…n
用dist(u,v,k)表示u,v两点间,只使用前k个顶点的最短距离
递推式:dist(u,v,k)=min{dist(u,v,k-1), dist(u,k,k-1)+dist(k,v,k-1)}//注意k在前两个变量时表示第k个顶点
algo:
for i = 1 to n do
| for j = 1 to n do
| | dist(i, j, 0) = ∞;
| end
end
for all (i,j) ∈ E do
| dist(i, j, 0) = l(i,j);
end
for k = 1 to n do
| for i = 1 to n do
| | for j = 1 to n do
| | | dist(i, j, k) = min{dist(i,j,k − 1),dist(i,k,k − 1) + dist(k,j,k − 1)};
| | end
| end
end背包问题
问题描述:背包容量W,物品有n种,物品i有价值v[i]和体积w[i],物品个数无限,如何装价值最高?
构建子问题:
![$K(w)=max_{i:w[i]\leq w}\{ K(w-w[i])+v[i]\} $](https://www.smzytyzg.tw.cn/wp-content/ql-cache/quicklatex.com-f8a6fa83c2df7b94e3ea9e05e42c6522_l3.png "Rendered by QuickLaTeX.com")
algo:
K(0) = 0;
for w = 1to W do
| K(w) =maxi:w[i]≤w{K(w-w[i])+v[i]};
end
return(K(W));时间复杂度:O(n·W)
如果个数只有1个?
algo:
Initialize all K(0,j) = 0 and all K(w,0) = 0;
for w = 1 to W do//求出容量为w时的最大价值
| for j = 1 to n do//求出只有前j个物品时的最大值
| | if wj > w then K(w,j) = K(w,j-1);
| | K(w,j) =max{K(w-wj,j-1)+vj,K(w,j-1)};//在重量为w-wj的基础上放入第j个物品或不放入
| end
end
return(K(W,n));时间复杂度:O(n·W)
网络流
最大流最小割
问题描述:
- 最大流:有向图,每条边有最大流量,问从s到t的最大流量是多少
- 最小割:有向图,每条边有权值,用一个割将s和t分开,切割的最小权值是多少
证明最大流等于最小割
令f为图上的流,(A,B)为图上的割,当且仅当val(f)=cap(A,B),f为最大流且(A,B)为最小割
证明:
首先证明对任意流f和任意割(A,B),有val(f)≤cap(A,B)

因此流等于割时,流是最大流,割是最小割
福特·福克森算法
- 从所有边流量为零开始
- 找到一条从s到t的路径,使流量尽可能大
- 因为我们需要有将一个流“取消”能力,所以如果在第二步中占用了边(u,v)上f的流量,就添加一条(v,u)上容量为f的新边
- 重复做2和3,直到找不到一条s到t的路径
例:
原图:
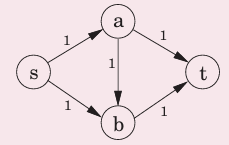
找到路径sabt,
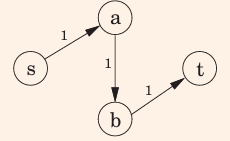
找到路径sbat,使用了上一步添加的e(b,a)
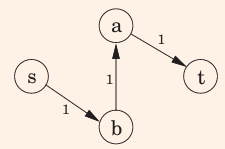
最终结果:
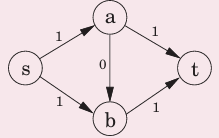
FORD–FULKERSON()
for each edge e ∈ E do
| f(e)←0
end
Gf ←residual network of G with respect to flow f;
while there exists an s t path P in Gf do
| f ←AUGMENT(f,P);
| UPDATE(Gf);
end
RETURN f;时间复杂度:假设最大流的值是C,我们最差每次可以增加1,所以时间复杂度是O(C|E||V|)(任意坏的),如果容量是无理数甚至无法终止
下面我们会介绍几种优化方法,基于不同的增广路径选取策略,对福特·福克森算法做优化
容量放缩算法Capacity-Scaling Algorithm
想法:每次选取容量较大的增广路径
算法:使用一个逐渐变小的Δ,优先考虑容量大于Δ的边,用尽这些边后缩小Δ,最终考虑所有边
CAPACITY-SCALING(G)
for each edge e ∈ E do
| f(e)←0
end
∆←largest power of 2 ≤ C;
while ∆ ≥ 1 do
| Gf(∆) ←∆-residual network of G with respect to flow f;
| while there exists an s t path P in Gf(∆) do
| | f ←AUGMENT(f, P);
| | UPDATE(G∆(f));
| end
| ∆=∆/2;
end
RETURN f;C是最大边长,且最小边长为1
证明正确性:最终Δ会取到1,Δ取1时,每条边都会被考虑,相当于福特福克森算法
时间复杂度:外层循环运行1+logC次,内层循环每次最多增广2|E|次,O(|E|2logC)
Edmonds-Karp算法
想法:选取最短的增广路径
算法:将DFS、BFS混合改为只使用BFS
EDMONDS–KARP’S ALGORITHM(G)
for each edge e ∈ E do
| f(e)←0
end
Gf ←residual network of G with respect to flow f;
while there exists an s→t path in Gf do
| P ←BFS(Gf);
| f ←AUGMENT(f, P);
| UPDATE(Gf);
end
RETURN f;时间复杂度:O(|V||E|2)
Dinitz’ Algorithm
- 从s开始,尝试找一条到t的路径
- 如果找到路径,则在原图中删去对应的流
- 如果中间走到点v卡住,没有路径,则删去点v,并回溯到上一个点
时间复杂度:O(|V|2|E|)
单位容量网络
二分匹配
问题描述:在一个图中,顶点被分为LR两个子集,找到最多的边横跨LR,且每个顶点只使用一次
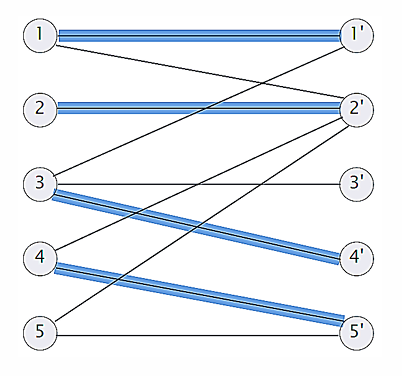
规约到如下流问题
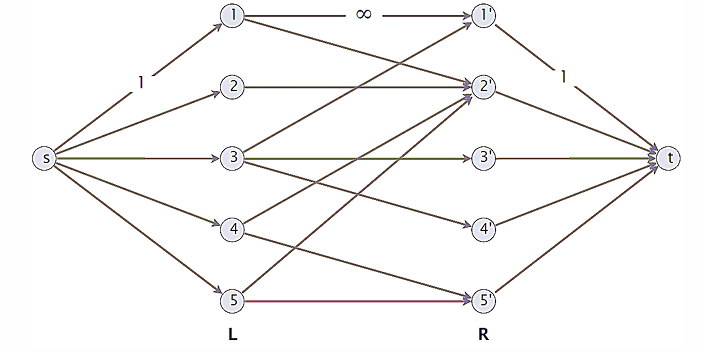
时间复杂度:O(|E||V|)(使用福特福克森算法,因为C一定)
完美匹配
在二分匹配的基础上,使得每个顶点都有另一个顶点与之匹配
令N(S)为与S中顶点相连的顶点的集合,简单观察,发现对任意S,都需要有|N(S)|≥|S|,问题才有可能有解(必要性)
Hall’s Marriage Theorem:二分图有完美匹配,当且仅当对任意S,都有|N(S)|≥|S|
证明:必要性易得
充分性:
使用反证法,若没有完美匹配,则必有一个子集S满足|N(S)|<|S|
假设图G(L∪R,E)没有完美匹配,令E中所有边容量为∞,添加源点S连接L,汇点T连接R,构成图G’
则在图G’上找到的最小割(A,B)不会包含任何一条E上的边(因为权值为∞)
令LA=L∩A,LB=L∩B,RA=R∩A,RB=R∩B;
cap(A,B)=|RA|+|LB|<|LA|+|LB|=|L|
则|RA|<|LA|,
LA即为满足条件的子集S
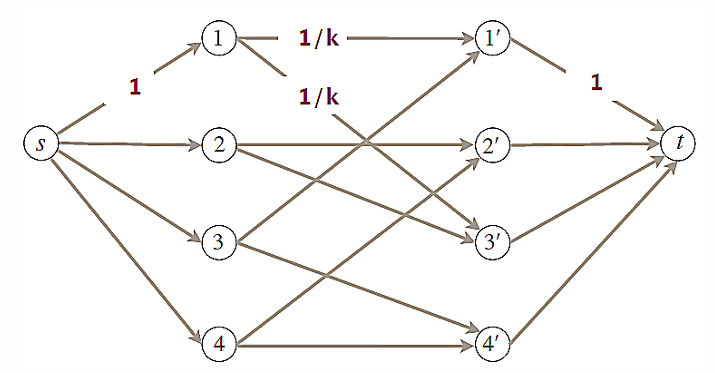
Hackathon Problem
问题描述:在二分图中,L中任意顶点v都有N(v)=k,R中任意顶点都有N(v)=k
这样的图一定有完美匹配
证明:我们希望找到一个流量为|L|=|R|的流,令L到R的每条边容量为1/k,其余边容量为1,每条边流满的时候正好满足流量要求。
Simple Unit-Capacity Networks
问题描述:在最大流最小割问题中,所有边容量均为1,并且对于每个非s、t的顶点,或入度为1,或出度为1(如上图)
使用Dinitz’算法,时间复杂度为O(|E||V|1/2)
证明:
- 每一次找到一条路径,耗费O(|E|)(每次找到一条路径,都要全部删去路径)
- 在|V|1/2次增广后,val(f*)≤val(f)+|V|1/2(在|V|1/2次增广后,最短路径长度大于|V|1/2,因此level graph至少|V|1/2层;前|V|1/2层至少有一层的顶点数量小于等于|V|1/2(平均值),因此至多再找到|V|1/2条路径,就无法找到其他路径)
- O(|V|1/2)次增广足够让流达到最优值
Edge-Disjoint Paths
问题描述:在有向无环图中,找出由源点s到汇点t最多的边不相交的路径
令每条边容量为一,求最大流即可
Network Connectivity
问题描述:在图中,去掉最少数量的边,使得点s到点t不存在路径
令每条边容量为一,求最小割即可
从s到t的边不相交路径的个数等同于使s到t不存在路径需要去掉的最少的边的个数
线性规划
线性规划问题的定义:给定一系列变量,给变量赋值,使得变量的值满足一系列等式及不等式,并使目标函数最大化/最小化
除了Infeasible(不存在可解空间)和Unbounded(可解空间无边界,这种情况也可能在顶点上)两种情况,线性规划的最优解都在顶点上
浅谈单纯形法Simplex Method
爬山法。在多边形的顶点上,移动到值更优的邻居,直到没有邻居比自己更优。
问题:怎么解出顶点;怎么确定邻居
顶点:二维两个不等式取等号的点;n维:n个不等式取等号的点。可能出现在可解空间外,去除即可
邻居:n维情况下,两个顶点中n个顶点只有1个不同。但是一个顶点可能有n+1个等式取等,引发“退化”问题
整数线性规划
如果顶点坐标不是整数(包括使用变换之后),而我们依然要求找到最优的整数解,没有多项式时间算法
对偶问题
注意maxmize→minimize
原问题:

令:

不等号在

时满足
对偶问题:

原问题:

令:

不等号在

时满足
对偶问题:

Theorem:如果原线性规划有有界(bounded)最优值,那么对偶问题也有有界最优值,且两个最优值重合
对偶的应用:
1.将两个不相关的问题联系起来(最大流→最小割)
2.假设我们通过单纯形法得到了一个顶点,我们如何确定
线性规划标准型
线性规划问题多种多样:max/min;等式/不等式;变量非负/任意;希望转换成一种标准格式,然后用一种方式解决
转换方式:
- max↔min:*-1
- 等式ax=b→不等式ax≥b,ax≤b;不等式ax>b→等式ax+s=b;s>0
- 负数→正数:定义x+和x–,x+和x–均非负,x替换成x+-x–
定义线性规划标准型:
- 变量非负
- 等式
- minimize
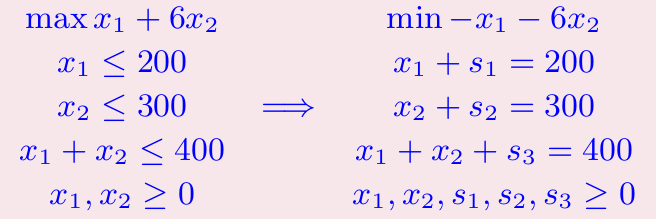
单纯形法算法Simplex Algorithm
Simplex:v是一个顶点,v‘是其邻居,v’有更好的value,则令v=v‘
顶点:某些超平面(线、面、超平面)相交的唯一的点(避免面面成线,所以强调唯一)
选取一些不等式,如果恰有一个点使这些不等式取等,那么这个点是顶点
邻居:n维空间中,如果两个顶点取等的不等式中有n-1个相同,则两点为邻居
算法:
- 在每次迭代中
- 从原点开始,检查邻居是否有更优的值,如果自己是最优的,则停止
- 如果有则移动过去
- 把坐标系原点移到当前点
为什么每次都要从原点开始?
- 如果目标函数中所有变量的系数都是负的(当我们一直移动到原点,最终目标函数会变成这样),那么原点就是最优值。(如maxmize -x1-3x2+5,最优值就是5)
- 当变量都为0时,我们可以很方便地找到邻居(如x1+2x2≤4,则邻居为(4,0) ,(0,2))
对线性规划进行坐标变换
从(0,0)开始增加x2,我们发现下一个触碰到的不等式是-x1+x2≤3,即找到一个邻居(0,3)
令y1=x1,y2=3+x1-x2≥0(注意新变量一定要≥0),可以将左边的原问题通过坐标变换变为右边的新问题

重复上面的步骤,我们增加y1,得到新邻居(1,0)
令z1=3-3y1+2y2,z2=y2,再得到新问题,可以发现目标函数中系数都为负,最优值是22

如何找到第一个顶点

我们可以通过上面这种方式,在原问题基础上找到一个新问题,新问题很容易找到一个顶点:xi=0;sj=0;z1=200,z2=300,z3=400
在这个顶点基础上解出线性规划,最优值显然会在zk=0时取到(如果取不到显然原问题infeasible),那么就会得到一个原问题的顶点
解决问题
退化问题
问题描述:n维空间,同一个点有大于n个不等式取等号,会导致顶点的邻居是其自己
解决方法:加个小扰动
Unbounded问题
问题描述:进行坐标变换时,发现永远不会碰到不等式,导致值一直增加
解决方法:设定一个max值,越界报错
时间复杂度
给定n个变量,m个约束(不包含xi≥0),最差情况下我们需要访问每个顶点,顶点个数为

是指数级的算法,但是在实际表现上很好
最短路径
Dijkstra算法的线性规划形式

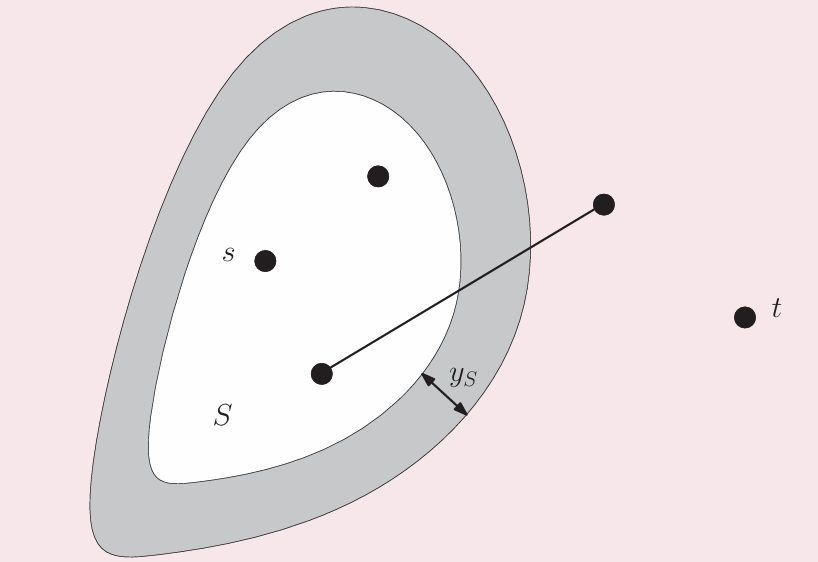
边界收缩,增加dt来找到边界
从最短路径问题出发
将图割成S、T两部分,其中s点在S,t点在T;将这个割写作S,δ(S)是S经过的所有边的集合;所有符合条件的割S的集合写作C。最短路径问题可以用下面的整数线性规划问题描述

第一个不等式保证了在取任意一个割的时候,都会有至少一条边被穿过,也就保证了路径连续
目标函数保证了dist最小
优化:
- 将xe∈{0,1}修改为0≤xe≤1:因为最优值都在整数点,所以可以
- 进一步,直接0≤xe:因为min保证了最优值靠近原点,所以可以不用≤1
最终形式:

取对偶:

对应Moat(护城河)问题:在从s到t间筑造护城河,使得护城河宽度最宽
最大流最小割问题
最大流问题可以用下面的线性规划问题描述:
假定边e(i,j)的最大流量为cij,实际流量为fij
一般形式:最大化流,流量小于最大流量,流入等于流出

另一种形式:加一条t到s的边,容量∞,同样max流量,可以将=改为≤(方便求对偶),因为是一个环,f1≤f2≤…≤fn≤f1,注意E包含e(t,s)

集合覆盖
NP问题
规约

将A规约到B的一个特殊情况,然后解决B,我们也就得到了一个A的解
注意是A比B简单(至少在描述上是简单的)
规约的三个用法:必考必出错
- 解决:将一个未知问题归约到一个已知问题,已知问题有一个算法,则我们得到一个未知问题的算法
- 证明:将一个已知问题归约到一个未知问题,我们可以证明未知问题比已知问题难
评估:将一个未知问题归约到一个已知问题,我们可以估计未知问题的难度
一般情况下,证明和评估只取其一,即两个问题无法互相规约,否则就是一个问题
判定、搜索、优化问题
一个问题有判定、搜索、优化三个版本,三个版本可以在多项式时间内互相规约
- 判定问题回答yes/no(是否存在一个≤k的顶点覆盖)
- 搜索问题回答一个解(是否存在一个=k的顶点覆盖)
- 优化问题回答一个最优解(找到一个最小的顶点覆盖)
最大独立集、最小顶点覆盖、最大团
问题描述:
最大独立集:在图中找到一组顶点,两两间无边,使此独立集最大化
最小顶点覆盖:在图中找到一组顶点,使得每条边都至少有1个顶点被覆盖,使此顶点覆盖最小化
最大团:在图中找到一组顶点,使得顶点间两两有边(区分强连通分量SCC,SCC只要求两两间有路径),使此集合最大化
独立集⇔团:原图中两两无边的独立集,对应补图中两两有边的团
独立集⇔顶点覆盖:假设最大独立集S,则V\S为最小顶点覆盖(V\S中所有顶点都与S相连)
三个问题实际上是一个问题,可以互相规约
集合覆盖问题
问题描述:输入集合B,和B的一些子集S1,S2…Sm;输出选择的Si,其并集为B,使选择的Si数量最小
顶点覆盖是一个特殊的集合覆盖,在顶点在集合中出现且仅出现2次的情况下。(将顶点覆盖归约到了集合覆盖上)
可满足性问题——SAT问题
SAT→3-SAT
3-SAT问题:在SAT问题的基础上,每个语句至多3个变量
我们只需要将SAT中变量数多于3的语句拆分


两个式子的可满足性相同(记得证两边)
为了在硬件上求解3-SAT问题,我们需要限制每个变量只出现3次以下(仍然是一个困难问题,但可以用硬件解决)。如果变量x出现在三个以上的子句中,我们可以将其替换为x1x2…xn,然后添加下面的语句,这个语句可以保证xi的取值一致

3-SAT→最大独立集
- 将3-SAT中的每个语句写成一个三角形,顶点两两相连
- 将不同三角形间,将一个值与其相反取值相连
- 假设原来有m个子句,则在图上找一个大小为m的独立集
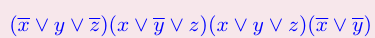
独立集中的每个点,都意味着一条语句为真,而我们又避免了一个值与其相反的取值同时被选取
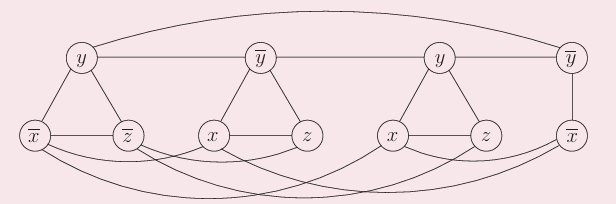
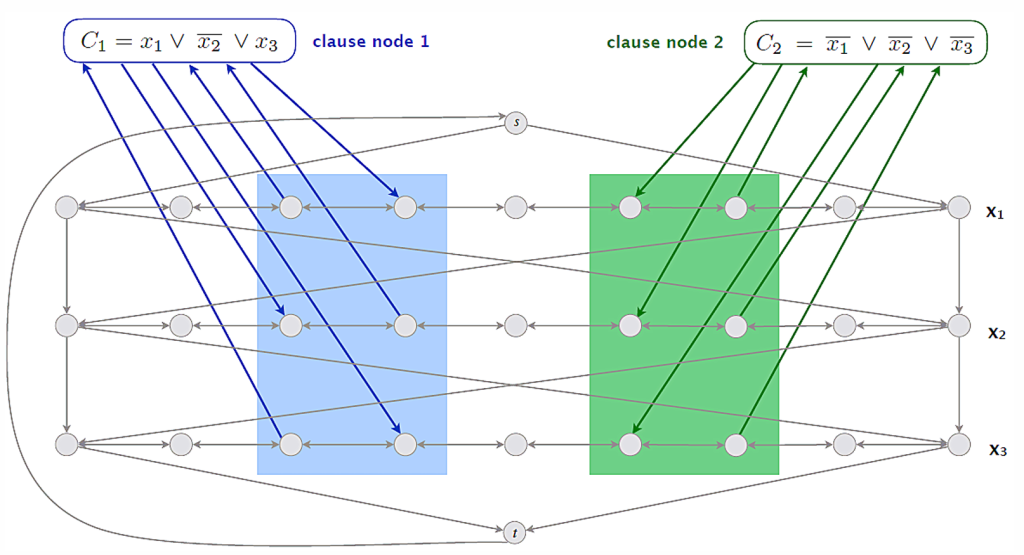
3-SAT→有向汉密尔顿环
使用每一行代表3-SAT问题中的每个变量,使用汉密尔顿环的方向代表取值,如下图代表取值为FFT
对于每个子句,如果其包含某行的变量,则在该行的两个顶点之间添加一条路到该子句(单向),如果取值得到满足,汉密尔顿路径会经过子句的顶点,如果全部子句的节点都被经过,则代表都被满足,则3-SAT问题有解。
有向汉密尔顿环→汉密尔顿环
有向汉密尔顿环:在一个图中,找到一个环路,经过所有顶点且仅经过一次
汉密尔顿环:在一个图中,找到一个环路,经过所有顶点且仅经过一次
规约方法:将一个点v拆分成3个点vin,v,vout,强制无向图产生有序的路径

汉密尔顿环→旅行商人问题TSP
旅行商人问题:如何用最短的路径访问所有顶点(访问且仅访问一遍)并返回起点。(每两个顶点间均存在路径)
给定一个汉密尔顿环问题的图G,因为TSP问题需要完全图,所以将图补全,原来的边权值设为1,补充的边权值设为1+k,跑一遍TSP,看权值是否为|V|
3-SAT→子集和问题
子集和问题
给定值w和集合A,从A中选出某些值ai,使得

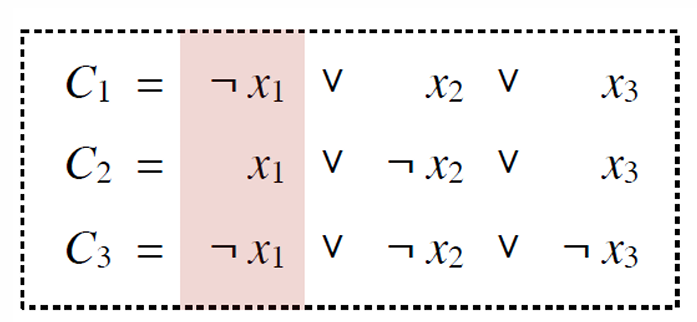
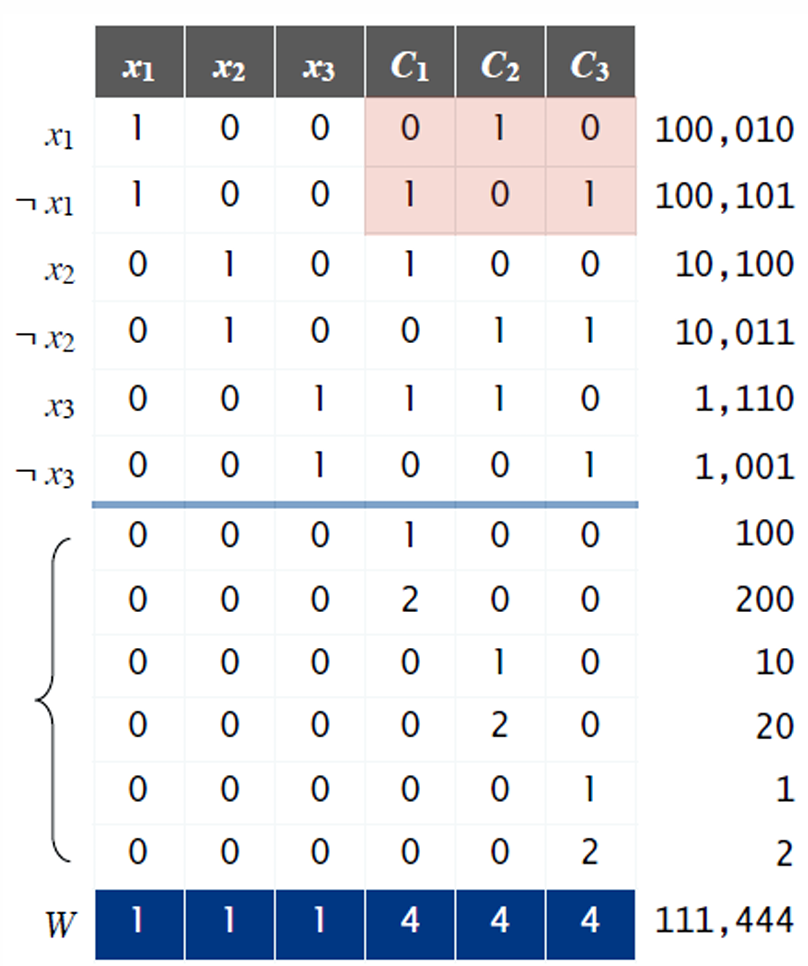
规约方法:前三位为1,代表xi或¬xi有且仅有一个被满足;同时会导致C1-C3产生0-3的值(如果是0则不被满足,大于0则被满足,为了得到一个确切的值,在横线下面添加了一些辅助值,可以将1-3的值变为4,便于设置子集和的w)
P、NP
P问题:给定一个判定问题,能在多项式时间内给出其一个解,如果不存在解也在多项式时间内停止
NP问题:给定一个判定问题,和一个可能的解,在多项式时间内可以验证这个解是否为这个问题的解
EXP问题:存在指数级算法的判定问题(比如输出一个集合的所有子集,不可避免的指数级问题)
NPC问题:所有NP问题都能在多项式时间内规约到的问题(NPC问题属于NP问题,所以NPC问题之间可以互相规约(并不直观),所有NPC问题是同一个问题)
co–问题:原问题回答T/F,补问题回答F/T(是否存在→是否不存在)
co-P问题:有多项式时间算法,co-P=P
co-NP问题:不一定有多项式时间的判定方法(SAT问题的补问题是判断一个CNF是否永久为假)
NP-hard问题:所有NP问题都能规约到的问题(NPC=NPH∩NP)
P⊆NP⊆EXP;P一定不等于EXP
SAT问题是第一个NPC问题(通过电路编码)
证明一个问题是NPC问题:首先证明是NP问题(多项式时间可验证),再将一个NPC问题规约到这个问题
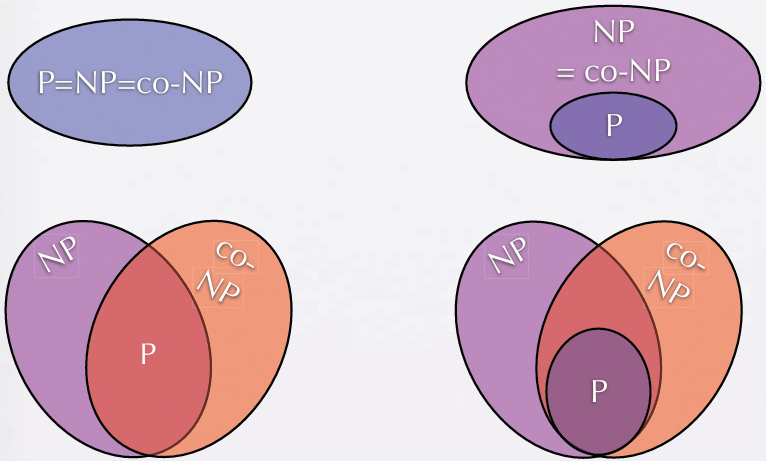
几种猜想,目前是右下角,学者倾向于左下是正确的,左上角是P=NP
近似算法
顶点覆盖
顶点覆盖、最大匹配
最小顶点覆盖:在图中找到一组顶点,使得每条边都至少有1个顶点被覆盖,使此顶点覆盖最小化
最大匹配:在图中找出不包含相同顶点的n个边,使n最大
最大匹配的贪婪算法(极大匹配算法):不断地找两个顶点都未被覆盖的边,并加入集合
最小顶点覆盖的贪婪算法:选取极大匹配的边的顶点
顶点覆盖贪婪算法的近似比:2
proof:显然,对于任意一个匹配(无论最大或极大),n≤OPT(选择的n条边至少需要n个顶点来覆盖,而我们至多选择了2n个顶点)
度权图上的顶点覆盖
问题描述:在最小顶点覆盖的基础上,为每个顶点添加权重(权重正比于节点的度数,w(vi)=c*deg(vi)),选取权重和最小的顶点覆盖
近似算法:直接选取所有顶点
近似比分析
每条边都至少有一个顶点在OPT中,所以OPT≥c*|E|
又有

故w(V)≤2*OPT,近似比为2
带权值的顶点覆盖
问题描述:在最小顶点覆盖的基础上,为每个顶点添加权重(不同于度权图,此处权值为任意正数),选取权重和最小的顶点覆盖
分层算法:
- 在图中选取一个度权比最高的顶点,度权比为w(vi)/deg(vi)
- 按照此度权比计算一个新图
- 原图权重减去新图权重(至少一个会被减到0,减到0的顶点添加到顶点覆盖中)
- 重复1-3直至图为空
原图:
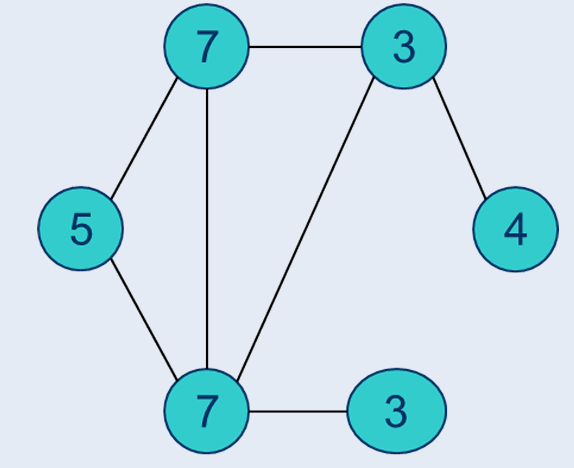
按最高度权比计算的新图:
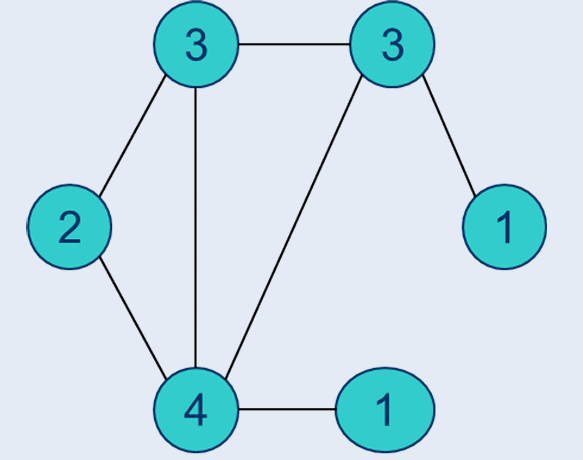
原图减去新图:
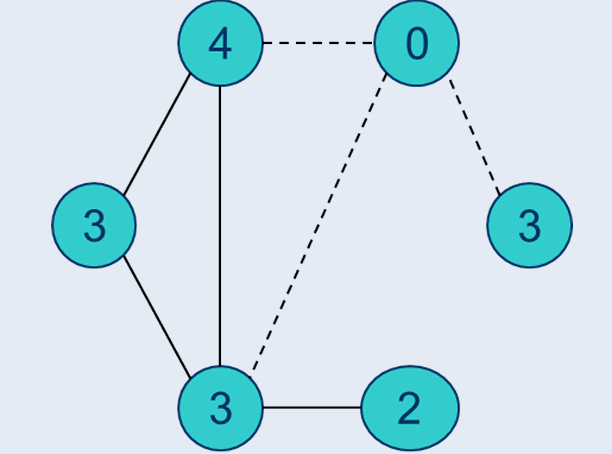
近似比分析
原图可以看作多个度权图的叠加,分层算法相当于在多个不同的度权图上进行近似算法,每个度权图的近似比都≤2,所以分层算法的近似比也为2
集合覆盖
集合覆盖
问题描述:
- 输入:集合B,集合B的子集S1,S2,…,Sm
- 输出:一系列Si,Si的并集是B
- cost:Si的数量
贪心算法:每次添加一个包含未被覆盖元素最多的Si
近似比分析
我们每次选取一个新的未被完全覆盖的集合,都至少会包含a/OPT个新元素,a为未被找到的元素的个数,也就有

应用1-x≤e-x
可以得到at=0时t=ln n·OPT,n为元素个数
此算法的近似比为ln n
带权重的集合覆盖问题
问题描述:
- 输入:集合B,集合B的子集S1,S2,…,Sm,每个Si有不同的权重c(Si)
- 输出:一系列Si,Si的并集是B
- cost:Si的数量
贪心算法:定义“平均权重”(权重/包含未添加元素的个数,c(Si)/|S-C|),每次添加平均权重最低的Si
近似比分析
我们计算第k个被覆盖的元素ek的权重:
选择ek时还有n-k+1个元素未被覆盖,最优解的总代价为OPT,则这些元素的平均代价≤OPT/(n-k+1),我们选择一个性价比最高的,price(ek)≤OPT/(n-k+1),对price(ek)k∈1-n求和,得到近似比如下
近似比:f=1+1/2+1/3+…+1/n≤ln n+1
斯坦纳树Steiner Tree
问题描述:无向图中的顶点分为两类:途径点(required)和斯坦纳点(Steiner),要求找出一颗生成树,经过所有途径点(可以经过斯坦纳点)。若图满足两边之和大于第三边,且图为完全图,则该问题称为度量斯坦纳树问题(metric Steiner tree problem)
斯坦纳树问题到度量斯坦纳树问题的规约
规约算法略复杂,直接给出结论
结论:在度量斯坦纳树问题中若有近似比为k的算法,则斯坦纳树问题中也有近似比为k的算法
度量斯坦纳树问题的近似算法
1.只在途径点上做最小生成树
近似比分析
假设原图OPT如下图中黑色线段(总长度OPT),方框为steiner顶点,圆圈为途径点。首先double所有边(总长度2*OPT),然后从一个途径点走一条不经过steiner顶点的路径(总路程=E),然后去掉最长的一条边(变成了一颗生成树)(总路程为P),途径点上的最小生成树表示为MST
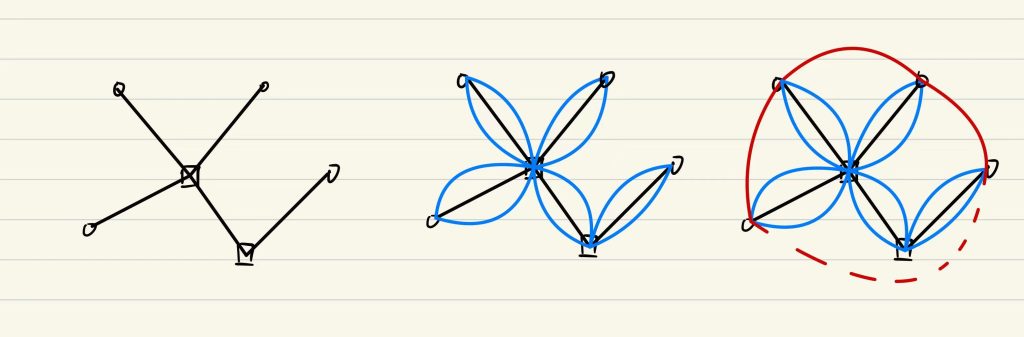
MST≤P≤E≤2*OPT
近似比为2
度量旅行商人问题TSP
旅行商人问题TSP:在完全图中,找到一条最短路径,经过所有顶点且仅经过一次,再返回起点
一般的TSP不存在任意近似算法,否则P=NP
度量旅行商人问题:图满足两边之和大于第三边
近似算法:
- 算出最小生成树
- 补出蓝色路径(欧拉回路)
- 沿蓝色路径走,如果访问过就跳到下一个节点
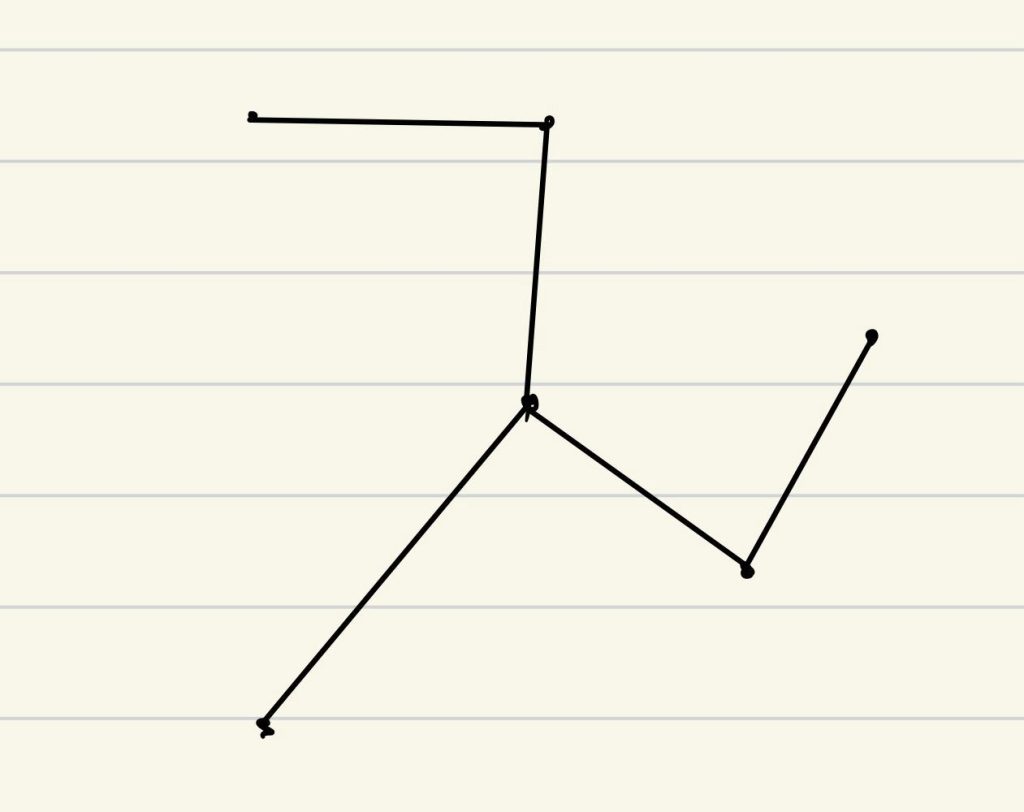


近似比为2
proof:MST≤OPT & Red_Path ≤2*MST=Blue_Path
更好的算法:“double edge”过于粗暴
- 我们挑出奇数度的顶点
- 将顶点配对后连接,同样可以得到一个欧拉回路(这里需要用最小的边连接,这个问题不难)

近似比1.5
proof:Blue_Path+Yellow_Path≤OPT,因为Blue_Path≤Yellow_Path,所以Blue_Path≤1/2OPT
Blue_Path+MST≤3/2OPT
PTAS、FPTAS、APTAS
PTAS:对任意给定的精度参数 ,算法都能在多项式时间内得到一个 近似解。(运行时间:对固定 ,关于 是多项式)
FPTAS:在PTAS基础上,要求运行时间关于 和 都是多项式
APTAS:在PTAS基础上,允许近似比增加一个常数项ALG≤(1+ε)OPT+cε
| 名称 | 保证 | 时间复杂度 |
|---|---|---|
| PTAS | ALG≤(1+ε)OPT | 固定 ε时关于n多项式 |
| FPTAS | ALG≤(1+ε)OPT | 关于n和1/ε都多项式 |
| APTAS | ALG≤(1+ε)OPT+cε | 固定ε时关于n多项式 |
背包问题
给定一个ε,我们可以得到一个近似度为1+ε的解,越接近1,算法复杂度越大,也是就FPTAS
无论物品是否可重复,对于背包问题我们有O(nW)的算法,但是一般我们认为n和W都很大,我们使用n和W的数位长度作为输入,所以是指数级算法
在使用1进制时(数位长度等于数位大小,5写作11111),背包问题是一个多项式时间算法
另外,除了之前讲过的O(nW)的算法,我们还有一个O(nV)的算法(填表时计算达到某个价值时,至少需要多少容量)
算法:
- vmax为最高的价值
- 令vi‘=⌊vi·n/ε·vmax⌋,n为元素个数(将V的位数变小了,当然也带来了一些误差,实际上就是忽略后几位,只比较前几位)
- 使用vi‘运行动态规划
得到的vi‘最大为n/ε,应用O(nV)的算法,时间复杂度为O(n3/ε)
近似比分析
令S为原问题精确解的集合,K*为最优值;S’为得到的近似解,则有



装填问题
问题描述:给定n个物品,尺寸介于0-1之间,每个箱子尺寸为1,如何装配使用的箱子最小
近似算法:
- 每次任意取出1个物品,尝试放入当前未被填满的箱子
- 如果未被填满的箱子装不进去,则增加一个空箱子
近似比分析
nature:
若算法使用了m个箱子,则至少m-1个箱子是半满的,因此
近似比为2
近似比的极限是1.5,因为如果小于1.5,而我们得出的近似解是2个箱子,我们就确定了精确解一定是两个箱子,P=NP
更好的算法
假设n个物品中最小物品的体积为,物品有K种不同的体积;则每个箱子至多个物品,那么箱子装填的状态至多有种,所以至多有种打包方式,关于n仍是多项式级,遍历即可;
因此近似算法为:优先考虑体积大于的物品,通过遍历得出最优解,然后使用原先的算法填充
在时,近似比为ALG≤(1+2ε)OPT+1
基于线性规划的近似算法
我赌你不考
关于考试
6*15+1*10
图论
定理证明
- DAG,SCC
- 割定理
- 最短路径
- 最小生成树
图算法,基于SCC、最短路径等等
动态规划
一道具体题目
递归入口,结果位置,时空复杂度分析(压轴)
网络流
定理证明——最大流最小割
规约
线性规划
问题建模并求出对偶
NP问题
将一个已知问题归约到一个未知问题,我们可以证明未知问题比已知问题难
证明是NPC问题-两步(证明P时间内可验证,将NPC问题规约过去)
证明是NP问题(证明P时间内可验证)
概念性问题?
近似算法
近似算法设计
近似比证明
tight example